The Repository Design Pattern, defined by Eric Evens in his Domain Driven Design book, is one of the most useful and most widely applicable design patterns ever invented. Any application has to work with persistence and with some kind of list of items. These can be users, products, networks, disks, or whatever your application is about. If you have a blog for example, you have to deal with lists of blog posts and lists of comments. The problem that all of these list management logics have in common is how to connect business logic, factories and persistence.
The Factory Design Pattern
As we mentioned in the introductory paragraph, a Repository will connect Factories with Gateways (persistence). These are also design patterns and if you are not familiar with them, this paragraph will shed some light on the subject.
A factory is a simple design pattern that defines a convenient way to create objects. It is a class or set of classes responsible for creating the objects our business logic needs. A factory traditionally has a method called " and it will know how to take all the information needed to build an object and do the object building itself and return a ready-to-use object to the business logic.make()"
Here is a little bit more on the Factory Pattern in an older Nettuts+ tutorial: A Beginner's Guide to Design Patterns. If you prefer a deeper view on the Factory Pattern, check out the first design pattern in the Agile Design Patterns course we have on Tuts+.
The Gateway Pattern
Also known as "Table Data Gateway" is a simple pattern that offers the connection between the business logic and the database itself. Its main responsibility is to do the queries on the database and provide the retrieved data in a data structure typical for the programming language (like an array in PHP). This data is then usually filtered and modified in the PHP code so that we can obtain the information and variables needed to crate our objects. This information must then be passed to the Factories.
The Gateway Design Pattern is explained and exemplified in quite great detail in a Nettuts+ tutorial about Evolving Toward a Persistence Layer. Also, in the same Agile Design Patterns course the second design pattern lesson is about this subject.
The Problems We Need to Solve
Duplication by Data Handling
It may not be obvious at first sight, but connecting Gateways to Factories can lead to a lot of duplication. Any considerable sized software needs to create the same objects from different places. In each place you will need to use the Gateway to retrieve a set of raw data, filter and work that data to be ready to be sent to the Factories. From all these places, you will call the same factories with the same data structures but obviously with different data. Your objects will be created and provided to you by the Factories. This will, inevitably lead to a lot of duplication in time. And the duplication will be spread throughout distant classes or modules and will be difficult to notice and to fix.
Duplication by Data Retrieval Logic Reimplementation
Another problem we have is how to express the queries we need to do with the help of the Gateways. Each time we need some information from the Gateway we need to think about what do we exactly need? Do we need all the data about a single subject? Do we need only some specific information? Do we want to retrieve a specific group from the database and do the sorting or refined filtering in our programming language? All of these questions need to be addressed each time we retrieve information from the persistence layer through our Gateway. Each time we do this, we will have to come up with a solution. In time, as our application grows, we will be confronted with the same dilemmas in different places of our application. Inadvertently we will come up with slightly different solutions to the same problems. This not only takes extra time and effort but also leads to a subtle, mostly very difficult to recognize, duplication. This is the most dangerous type of duplication.
Duplication by Data Persistence Logic Reimplementation
In the previous two paragraphs we talked only about data retrieval. But the Gateway is bidirectional. Our business logic is bidirectional. We have to somehow persist our objects. This again leads to a lot of repetition if we want to implement this logic as needed throughout different modules and classes of our application.
The Main Concepts
Repository for Data Retrieval
A Repository can function in two ways: data retrieval and data persistence.
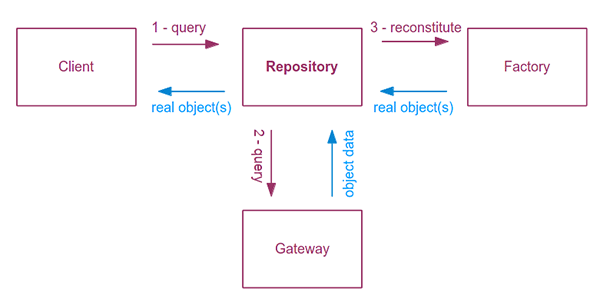
When used to retrieve objects from persistence, a Repository will be called with a custom query. This query can be a specific method by name or a more common method with parameters. The Repository is responsible to provide and implement these query methods. When such a method is called, the Repository will contact the Gateway to retrieve the raw data from the persistence. The Gateway will provide raw object data (like an array with values). Then the Repository will take this data, do the necessary transformations and call the appropriate Factory methods. The Factories will provide the objects constructed with the data provided by the Repository. The Repository will collect these objects and return them as a set of objects (like an array of objects or a collection object as defined in the Composite Pattern lesson in the Agile Design Patterns course).
Repository for Data Persistence
The second way a Repository can work is to provide the logic needed to be done in order to extract the information from an object and persist it. This can be as simple as serializing the object and sending the serialized data to the Gateway to persist it or as sophisticated as creating arrays of information with all the fields and state of an object.
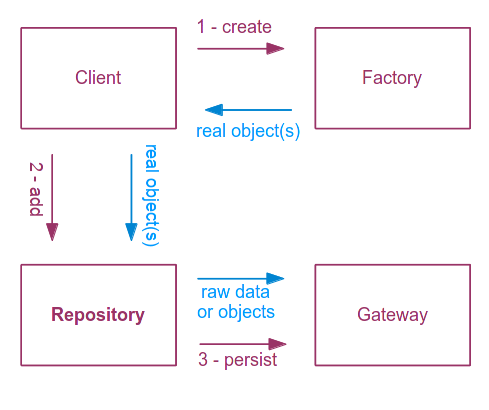
When used to persist information the client class is the one directly communicating with the Factory. Imagine a scenario when a new comment is posted to a blog post. A Comment object is created by our business logic (the Client class) and then sent to the Repository to be persisted. The repository will persist the objects using the Gateway and optionally cache them in a local in memory list. Data needs to be transformed because there are only rare cases when real objects can be directly saved to a persistence system.
Connecting the Dots
The image below is a higher level view on how to integrate the Repository between the Factories, the Gateway and the Client.
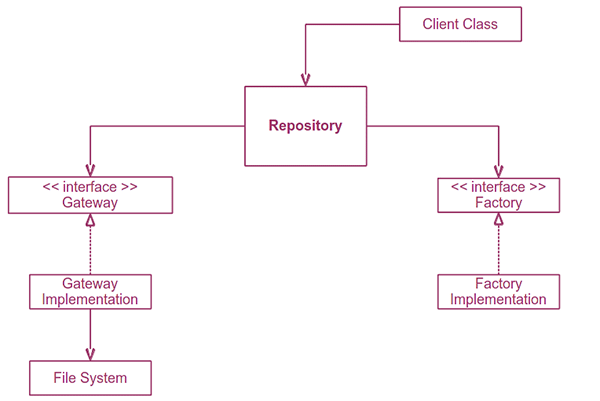
In the center of the schema is our Repository. On the left, is an Interface for the Gateway, an implementation and the persistence itself. On the right, there is an Interface for the Factories and a Factory implementation. Finally, on the top there is the client class.
As it can be observed from the direction of the arrows, the dependencies are inverted. Repository only depend on the abstract interfaces for Factories and Gateways. Gateway depends on its interface and the persistence it offers. The Factory depends only on its Interface. The client depends on Repository, which is acceptable because the Repository tends to be less concrete than the Client.
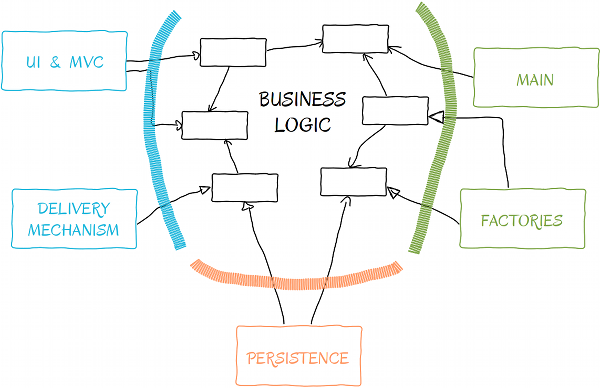
Put in perspective, the paragraph above respects our high level architecture and the direction of dependencies we want to achieve.
Managing Comments to Blog Posts With a Repository
Now that we've seen the theory, it is time for a practical example. Imagine we have a blog where we have Post objects and Comment objects. Comments belong to Posts and we have to find a way to persist them and to retrieve them.
The Comment
We will start with a test that will force us to think about what our Comment object should contain.
class RepositoryTest extends PHPUnit_Framework_TestCase {
function testACommentHasAllItsComposingParts() {
$postId = 1;
$commentAuthor = "Joe";
$commentAuthorEmail = "[email protected]";
$commentSubject = "Joe Has an Opinion about the Repository Pattern";
$commentBody = "I think it is a good idea to use the Repository Pattern to persist and retrieve objects.";
$comment = new Comment($postId, $commentAuthor, $commentAuthorEmail, $commentSubject, $commentBody);
}
}
At first glance, a Comment will just be a data object. It may not have any functionality, but that is up to the context of our application to decide. For this example just assume it is a simple data object. Constructed with a set of variables.
class Comment {
}
Just by creating an empty class and requiring it in the test makes it pass.
require_once '../Comment.php';
class RepositoryTest extends PHPUnit_Framework_TestCase {
[ ... ]
}
But that's far from perfect. Our test does not test anything yet. Let's force ourselves to write all the getters on the Comment class.
function testACommentsHasAllItsComposingParts() {
$postId = 1;
$commentAuthor = "Joe";
$commentAuthorEmail = "[email protected]";
$commentSubject = "Joe Has an Opinion about the Repository Pattern";
$commentBody = "I think it is a good idea to use the Repository Pattern to persist and retrieve objects.";
$comment = new Comment($postId, $commentAuthor, $commentAuthorEmail, $commentSubject, $commentBody);
$this->assertEquals($postId, $comment->getPostId());
$this->assertEquals($commentAuthor, $comment->getAuthor());
$this->assertEquals($commentAuthorEmail, $comment->getAuthorEmail());
$this->assertEquals($commentSubject, $comment->getSubject());
$this->assertEquals($commentBody, $comment->getBody());
}
To control the length of the tutorial, I wrote all the assertions at once and we will implement them at once as well. In real life, take them one by one.
class Comment {
private $postId;
private $author;
private $authorEmail;
private $subject;
private $body;
function __construct($postId, $author, $authorEmail, $subject, $body) {
$this->postId = $postId;
$this->author = $author;
$this->authorEmail = $authorEmail;
$this->subject = $subject;
$this->body = $body;
}
public function getPostId() {
return $this->postId;
}
public function getAuthor() {
return $this->author;
}
public function getAuthorEmail() {
return $this->authorEmail;
}
public function getSubject() {
return $this->subject;
}
public function getBody() {
return $this->body;
}
}
Except for the list of private variables, the rest of the code was generated by my IDE, NetBeans, so testing the auto generated code may be a little bit of overhead some times. If you are not writing these lines by yourself, feel free to do them directly and don't bother with tests for setters and constructors. Nevertheless, the test helped us better expose our ideas and better document what our Comment class will contain.
We can also consider these test methods and test classes as our "Client" classes from the schemas.
Our Gateway to Persistence
To keep this example as simple as possible, we will implement only an InMemoryPersistence so that we do not complicate our existence with file systems or databases.
require_once '../InMemoryPersistence.php';
class InMemoryPersistenceTest extends PHPUnit_Framework_TestCase {
function testItCanPerisistAndRetrieveASingleDataArray() {
$data = array('data');
$persistence = new InMemoryPersistence();
$persistence->persist($data);
$this->assertEquals($data, $persistence->retrieve(0));
}
}
As usual, we start with the simplest test that could possibly fail and also force us to write some code. This test creates a new InMemoryPersistence object and tries to persist and retrieve an array called data.
require_once __DIR__ . '/Persistence.php';
class InMemoryPersistence implements Persistence {
private $data = array();
function persist($data) {
$this->data = $data;
}
function retrieve($id) {
return $this->data;
}
}
The simplest code to make it pass is just to keep the incoming $data in a private variable and return it in the retrieve method. The code as it is right now does not care about the sent in $id variable. It is the simplest thing that could possibly make the test pass. We also took the liberty to introduce and implement an interface called Persistence.
interface Persistence {
function persist($data);
function retrieve($ids);
}
This interface defines the two methods any Gateway needs to implement. Persist and retrieve. As you probably already guessed, our Gateway is our InMemoryPersistence class and our physical persistence is the private variable holding our data in the memory. But let's get back to the implementation of this in memory persistence.
function testItCanPerisistSeveralElementsAndRetrieveAnyOfThem() {
$data1 = array('data1');
$data2 = array('data2');
$persistence = new InMemoryPersistence();
$persistence->persist($data1);
$persistence->persist($data2);
$this->assertEquals($data1, $persistence->retrieve(0));
$this->assertEquals($data2, $persistence->retrieve(1));
}
We added another test. In this one we persist two different data arrays. We expect to be able to retrieve each of them individually.
require_once __DIR__ . '/Persistence.php';
class InMemoryPersistence implements Persistence {
private $data = array();
function persist($data) {
$this->data[] = $data;
}
function retrieve($id) {
return $this->data[$id];
}
}
The test forced us to slightly alter our code. We now need to add data to our array, not just replace it with the one sent in to persists(). We also need to consider the $id parameter and return the element at that index.
This is enough for our InMemoryPersistence. If needed, we can modify it later.
Our Factory
We have a Client (our tests), a persistence with a Gateway, and Comment objects to persists. The next missing thing is our Factory.
We started our coding with a RepositoryTest file. This test, however, actually created a Comment object. Now we need to create tests to verify if our Factory will be able to create Comment objects. It seems like we had an error in judgment and our test is more likely a test for our upcoming Factory than for our Repository. We can move it into another test file, CommentFactoryTest.
require_once '../Comment.php';
class CommentFactoryTest extends PHPUnit_Framework_TestCase {
function testACommentsHasAllItsComposingParts() {
$postId = 1;
$commentAuthor = "Joe";
$commentAuthorEmail = "[email protected]";
$commentSubject = "Joe Has an Opinion about the Repository Pattern";
$commentBody = "I think it is a good idea to use the Repository Pattern to persist and retrieve objects.";
$comment = new Comment($postId, $commentAuthor, $commentAuthorEmail, $commentSubject, $commentBody);
$this->assertEquals($postId, $comment->getPostId());
$this->assertEquals($commentAuthor, $comment->getAuthor());
$this->assertEquals($commentAuthorEmail, $comment->getAuthorEmail());
$this->assertEquals($commentSubject, $comment->getSubject());
$this->assertEquals($commentBody, $comment->getBody());
}
}
Now, this test obviously passes. And while it is a correct test, we should consider modifying it. We want to create a Factory object, pass in an array and ask it to create a Comment for us.
require_once '../CommentFactory.php';
class CommentFactoryTest extends PHPUnit_Framework_TestCase {
function testACommentsHasAllItsComposingParts() {
$postId = 1;
$commentAuthor = "Joe";
$commentAuthorEmail = "[email protected]";
$commentSubject = "Joe Has an Opinion about the Repository Pattern";
$commentBody = "I think it is a good idea to use the Repository Pattern to persist and retrieve objects.";
$commentData = array($postId, $commentAuthor, $commentAuthorEmail, $commentSubject, $commentBody);
$comment = (new CommentFactory())->make($commentData);
$this->assertEquals($postId, $comment->getPostId());
$this->assertEquals($commentAuthor, $comment->getAuthor());
$this->assertEquals($commentAuthorEmail, $comment->getAuthorEmail());
$this->assertEquals($commentSubject, $comment->getSubject());
$this->assertEquals($commentBody, $comment->getBody());
}
}
We should never name our classes based on the design pattern they implement, but Factory and Repository represent more than just the design pattern itself. I personally have nothing against including these two words in our class's names. However I still strongly recommend and respect the concept of not naming our classes after the design patterns we use for the rest of the patterns.
This test is just slightly different from the previous one, but it fails. It tries to create a CommentFactory object. That class does not exist yet. We also try to call a make() method on it with an array containing all the information of a comment as an array. This method is defined in the Factory interface.
interface Factory {
function make($data);
}
This is a very common Factory interface. It defined the only required method for a factory, the method that actually creates the objects we want.
require_once __DIR__ . '/Factory.php';
require_once __DIR__ . '/Comment.php';
class CommentFactory implements Factory {
function make($components) {
return new Comment($components[0], $components[1], $components[2], $components[3], $components[4]);
}
}
And CommentFactory implements the Factory interface successfully by taking the $components parameter in its make() method, creates and returns a new Comment object with the information from there.
We will keep our persistence and object creation logic as simple as possible. We can, for this tutorial, safely ignore any error handling, validation and exception throwing. We will stop here with the persistence and object creation implementation.
Using a Repository to Persist Comments
As we've seen above, we can use a Repository in two ways. To retrieve information from persistence and also to persist information on the persistence layer. Using TDD it is, most of the time, easier to start with the saving (persisting) part of the logic and then use that existing implementation to test data retrieval.
require_once '../../../vendor/autoload.php';
require_once '../CommentRepository.php';
require_once '../CommentFactory.php';
class RepositoryTest extends PHPUnit_Framework_TestCase {
protected function tearDown() {
\Mockery::close();
}
function testItCallsThePersistenceWhenAddingAComment() {
$persistanceGateway = \Mockery::mock('Persistence');
$commentRepository = new CommentRepository($persistanceGateway);
$commentData = array(1, 'x', 'x', 'x', 'x');
$comment = (new CommentFactory())->make($commentData);
$persistanceGateway->shouldReceive('persist')->once()->with($commentData);
$commentRepository->add($comment);
}
}
We use Mockery to mock our persistence and inject that mocked object to the Repository. Then we call add() on the repository. This method has a parameter of type Comment. We expect the persistence to be called with an array of data similar to $commentData.
require_once __DIR__ . '/InMemoryPersistence.php';
class CommentRepository {
private $persistence;
function __construct(Persistence $persistence = null) {
$this->persistence = $persistence ? : new InMemoryPersistence();
}
function add(Comment $comment) {
$this->persistence->persist(array(
$comment->getPostId(),
$comment->getAuthor(),
$comment->getAuthorEmail(),
$comment->getSubject(),
$comment->getBody()
));
}
}
As you can see, the add() method is quite smart. It encapsulates the knowledge about how to transform a PHP object into a plain array usable by the persistence. Remember, our persistence gateway usually is a general object for all of our data. It can and will persist all the data of our application, so sending to it objects would make it do too much: both conversion and effective persistence.
When you have an InMemoryPersistence class like we do, it is very fast. We can use it as an alternative to mocking the gateway.
function testAPersistedCommentCanBeRetrievedFromTheGateway() {
$persistanceGateway = new InMemoryPersistence();
$commentRepository = new CommentRepository($persistanceGateway);
$commentData = array(1, 'x', 'x', 'x', 'x');
$comment = (new CommentFactory())->make($commentData);
$commentRepository->add($comment);
$this->assertEquals($commentData, $persistanceGateway->retrieve(0));
}
Of course if you do not have an in-memory implementation of your persistence, mocking is the only reasonable way to go. Otherwise your test will be just too slow to be practical.
function testItCanAddMultipleCommentsAtOnce() {
$persistanceGateway = \Mockery::mock('Persistence');
$commentRepository = new CommentRepository($persistanceGateway);
$commentData1 = array(1, 'x', 'x', 'x', 'x');
$comment1 = (new CommentFactory())->make($commentData1);
$commentData2 = array(2, 'y', 'y', 'y', 'y');
$comment2 = (new CommentFactory())->make($commentData2);
$persistanceGateway->shouldReceive('persist')->once()->with($commentData1);
$persistanceGateway->shouldReceive('persist')->once()->with($commentData2);
$commentRepository->add(array($comment1, $comment2));
}
Our next logical step is to implement a way to add several comments at once. Your project may not require this functionality and it is not something required by the pattern. In fact, the Repository Pattern only says that it will provide a custom query and persistence language for our business logic. So if our bushiness logic feels the need of adding several comments at once, the Repository is the place where the logic should reside.
function add($commentData) {
if (is_array($commentData))
foreach ($commentData as $comment)
$this->persistence->persist(array(
$comment->getPostId(),
$comment->getAuthor(),
$comment->getAuthorEmail(),
$comment->getSubject(),
$comment->getBody()
));
else
$this->persistence->persist(array(
$commentData->getPostId(),
$commentData->getAuthor(),
$commentData->getAuthorEmail(),
$commentData->getSubject(),
$commentData->getBody()
));
}
And the simplest way to make the test pass is to just verify if the parameter we are getting is an array or not. If it is an array, we will cycle through each element and call the persistence with the array we generate from one single Comment object. And while this code is syntactically correct and makes the test pass, it introduces a slight duplication that we can get rid of quite easily.
function add($commentData) {
if (is_array($commentData))
foreach ($commentData as $comment)
$this->addOne($comment);
else
$this->addOne($commentData);
}
private function addOne(Comment $comment) {
$this->persistence->persist(array(
$comment->getPostId(),
$comment->getAuthor(),
$comment->getAuthorEmail(),
$comment->getSubject(),
$comment->getBody()
));
}
When all the tests are green, it is alway time for refactoring before we continue with the next failing test. And we did just that with the add() method. We extracted the addition of a single comment into a private method and called it from two different places in our public add() method. This not only reduced duplication but also opened the possibility of making the addOne() method public and letting the business logic decide if it wants to add one or several comments at a time. This would lead to a different implementation of our Repository, with an addOne() and another addMany() methods. It would be a perfectly legitimate implementation of the Repository Pattern.
Retrieving Comments With Our Repository
A Repository provides a custom query language for the business logic. So the names and functionalities of the query methods of a Repository is hugely up to the requirements of the business logic. You build your repository as you build your business logic, as you need another custom query method. However, there are at least one or two methods that you will find on almost any Repository.
function testItCanFindAllComments() {
$repository = new CommentRepository();
$commentData1 = array(1, 'x', 'x', 'x', 'x');
$comment1 = (new CommentFactory())->make($commentData1);
$commentData2 = array(2, 'y', 'y', 'y', 'y');
$comment2 = (new CommentFactory())->make($commentData2);
$repository->add($comment1);
$repository->add($comment2);
$this->assertEquals(array($comment1, $comment2), $repository->findAll());
}
The first such method is called findAll(). This should return all the objects the repository is responsible for, in our case Comments. The test is simple, we add a comment, then another one, and finally we want to call findAll() and get a list containing both comments. This is however not accomplish-able with our InMemoryPersistence as it is at this point. A small update is required.
function retrieveAll() {
return $this->data;
}
That's it. We added a retrieveAll() method which just returns the whole $data array from the class. Simple and effective. It's time to implement findAll() on the CommentRepository now.
function findAll() {
$allCommentsData = $this->persistence->retrieveAll();
$comments = array();
foreach ($allCommentsData as $commentData)
$comments[] = $this->commentFactory->make($commentData);
return $comments;
}
findAll() will call the retrieveAll() method on our persistence. That method provides a raw array of data. findAll() will cycle through each element and use the data as necessary to be passed to the Factory. The factory will provide one Comment a time. An array with these comments will be built and returned at the end of findAll(). Simple and effective.
Another common method you will find on repositories is to search for a specific object or group of objects based on their characteristic key. For example, all of our comments are connected to a blog post by a $postId internal variable. I can imagine that in our blog's business logic we would almost always want to find all the comments related to a blog post when that blog post is displayed. So a method called findByPostId($id) sounds reasonable to me.
function testItCanFindCommentsByBlogPostId() {
$repository = new CommentRepository();
$commentData1 = array(1, 'x', 'x', 'x', 'x');
$comment1 = (new CommentFactory())->make($commentData1);
$commentData2 = array(1, 'y', 'y', 'y', 'y');
$comment2 = (new CommentFactory())->make($commentData2);
$commentData3 = array(3, 'y', 'y', 'y', 'y');
$comment3 = (new CommentFactory())->make($commentData3);
$repository->add(array($comment1, $comment2));
$repository->add($comment3);
$this->assertEquals(array($comment1, $comment2), $repository->findByPostId(1));
}
We just create three simple comments. The first two have the same $postId = 1, the third one has $postID = 3. We add all of them to the repository and then we expect an array with the first two ones when we do a findByPostId() for the $postId = 1.
function findByPostId($postId) {
return array_filter($this->findAll(), function ($comment) use ($postId){
return $comment->getPostId() == $postId;
});
}
The implementation couldn't be simpler. We find all the comments using our already implemented findAll() method and we filter the array. We have no way to ask the persistence to do the filtering for us, so we will do it here. The code will query each Comment object and compare its $postId with the one we sent in as parameter. Great. The test passes. But I feel we missed something.
function testItCanFindCommentsByBlogPostId() {
$repository = new CommentRepository();
$commentData1 = array(1, 'x', 'x', 'x', 'x');
$comment1 = (new CommentFactory())->make($commentData1);
$commentData2 = array(1, 'y', 'y', 'y', 'y');
$comment2 = (new CommentFactory())->make($commentData2);
$commentData3 = array(3, 'y', 'y', 'y', 'y');
$comment3 = (new CommentFactory())->make($commentData3);
$repository->add(array($comment1, $comment2));
$repository->add($comment3);
$this->assertEquals(array($comment1, $comment2), $repository->findByPostId(1));
$this->assertEquals(array($comment3), $repository->findByPostId(3));
}
Adding a second assertion to obtain the third comment with the findByPostID() method reveals our mistake. Whenever you can easily test extra paths or cases, like in our case with a simple extra assertion, you should. These simple extra assertions or test methods can reveal hidden problems. Like in our case, array_filter() does not reindex the resulting array. And while we have an array with the correct elements, the indexes are messed up.
1) RepositoryTest::testItCanFindCommentsByBlogPostId Failed asserting that two arrays are equal. --- Expected +++ Actual @@ @@ Array ( - 0 => Comment Object (...) + 2 => Comment Object (...) )
Now, you may consider this a shortcoming of PHPUnit or a shortcoming of your business logic. I tend to be rigorous with array indexes because I burned my hands with them a few times. So we should consider the error a problem with our logic in the CommentRepository.
function findByPostId($postId) {
return array_values(
array_filter($this->findAll(), function ($comment) use ($postId) {
return $comment->getPostId() == $postId;
})
);
}
Yep. That simple. We just run the result through array_values() before returning it. It will nicely reindex our array. Mission accomplished.
Final Thoughts
And that's mission accomplished for our Repository also. We have a class usable by any other business logic class which offers an easy way to persist and retrieve objects. It also decouples the business logic from the factories and data persistence gateways. It reduced logic duplication and significantly simplifies the persistence and retrieval operations for our comments.
Remember, this design pattern can be used for all types of lists and as you start using it, you will see its usefulness. Basically, whenever you have to work with several objects of the same type, you should consider introducing a Repository for them. Repositories are specialized by object type and not general. So for a blog application, you may have distinct repositories for blog posts, for comments, for users, for user configurations, for themes, for designs, for or anything you may have multiple instances of.
And before concluding this, a Repository may have its own list of objects and it may do a local caching of objects. If an object can not be found in the local list, we retrieve it from the persistence, otherwise we serve it from our list. If used with caching, a Repository can be successfully combined with the Singleton Design Pattern.
As usual, thank you for your time and I sincerely hope I taught you something new today.

Comments