One of the most confusing design pattern is persistence. The need for an application to persist its internal state and data is so tremendous that there are likely tens - if not hundreds - of different technologies to address this single problem. Unfortunately, no technology is a magic bullet. Each application, and sometimes each component of the application, is unique in its own way - thus, requiring a unique solution.
In this tutorial, I will teach you some best practices to help you determine which approach to take, when working on future applications. I will briefly discuss some high level design concerns and principles, followed by a more detailed view on the Active Record design pattern, combined with a few words about the Table Data Gateway design pattern.
Of course, I will not merely teach you the theory behind the design, but I will also guide you through an example that begins as random code and transforms into a structured persistence solution.
Two Tales of a Single Application
The Database is for Data, not for Code
Today, no programmer can understand this archaic system.
The oldest project I have to work on began in the year 2000. Back then, a team of programmers started a new project by evaluating different requirements, thought about the workloads the application will have to handle, tested different technologies and reached a conclusion: all the PHP code of the application, except the index.php file, should reside in a MySQL database. Their decision may sound outrageous today, but it was acceptable twelve years ago (OK... maybe not).
They started by creating their base tables, and then other tables for each web page. The solution worked... for a time. The original authors knew how to maintain it, but then each author left one by one--leaving the code base in the hands of other newcomers.
Today, no programmer can understand this archaic system. Everything starts with a MySQL query from index.php. The result of that query returns some PHP code that executes even more queries. The simplest scenario involves at least five database tables. Naturally, there are no tests or specifications. Modifying anything is a no-go, and we simply have to rewrite the entire module if something goes wrong.
The original developers ignored the fact that a database should only contain data, not business logic or presentation. They mixed PHP and HTML code with MySQL and ignored high level design concepts.
The HTML is for Presentation and Presentation Only
All applications should concentrate on respecting a clean, high level design.
As time passed, the new programmers needed to add additional features to the system while, at the same time, fixing old bugs. There was no way to continue using MySQL tables for everything, and everyone involved in maintaining the code agreed that its design was horribly flawed. So the new programmers evaluated different requirements, thought about the workloads the application will have to handle, tested different technologies and reached a conclusion: they decided to move as much code as possible to the final presentation. Again, this decision may sound outrageous today, but it was light years from the previous outrageous design.
The developers adopted a templating framework and based the application around it, starting every new feature and module with a new template. It was easy; the template was descriptive and they knew where to find the code that performs a specific task. But that's how they ended up with template files containing the engine's Domain Specific Language (DSL), HTML, PHP and of course MySQL queries.
Today, my team just watches and wonders. It is a miracle that many of the views actually work. It can take a hefty amount of time just to determine how information gets from the database to the view. Like its predecessor, it's all a big mess!
Those developers ignored the fact that a view should not contain business or persistence logic. They mixed PHP and HTML code with MySQL and ignored high level design concepts.
High Level Application Design
A mock is an object that acts like its real counterpart, but doesn’t execute the real code.
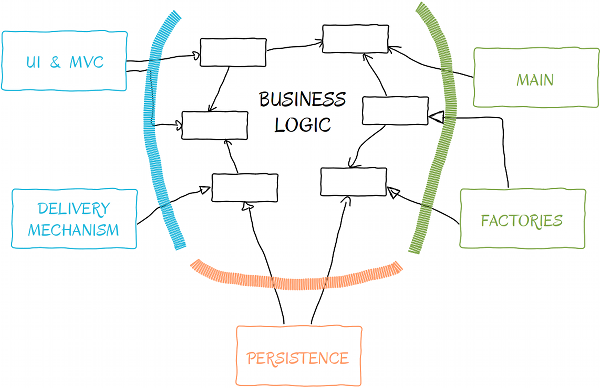
All applications should concentrate on respecting a clean, high level design. This is not always achievable, but it should be a high priority. A good high level design has well-isolated business logic. Object creation, persistence, and delivery are outside of the core and dependencies point only toward the business logic.
Isolating the business logic opens the door to great possibilities, and everything becomes somewhat of a plugin, if the external dependencies always point towards the business logic. For example, you could swap the heavy MySQL database with a lightweight SQLite3 database.
- Imagine being able to drop your current MVC framework and replacing it with another, without touching the business logic.
- Imagine delivering the results of your application through a third party API and not over HTTP, or changing any third party technology you use today (except the programming language of course) without touching the business logic (or without much hassle).
- Imagine making all these changes and your tests would still pass.
Implementing a Working Solution for Persisting a Blog Post
To better identify the problems with a bad, albeit working, design, I will start with a simple example of, you guessed it, a blog. Throughout this tutorial, I will follow some test-driven development (TDD) principles and make the tests easily understandable - even if you don't have TDD experience. Let's imagine that you use a MVC framework. When saving a blog post, a controller named BlogPost executes a save() method. This method connects to an SQLite database to store a blog post in the database.
Let's create a folder, called Data in our code's folder and browse to that directory in the console. Create a database and a table, like this:
$ sqlite3 MyBlog SQLite version 3.7.13 2012-06-11 02:05:22 Enter ".help" for instructions Enter SQL statements terminated with a ";" sqlite> create table BlogPosts ( title varchar(120) primary key, content text, published_timestamp timestamp);
Our save() method gets the values from the form as an array, called $data:
class BlogPostController {
function save($data) {
$dbhandle = new SQLite3('Data/MyBlog');
$query = 'INSERT INTO BlogPosts VALUES("' . $data['title'] . '","' . $data['content'] . '","' . time(). '")';
$dbhandle->exec($query);
}
}
This code works, and you can verify it by calling it from another class, passing a predefined $data array, like this:
$this->object = new BlogPostController; $data['title'] = 'First Post Title'; $data['content'] = 'Some cool content for the first post'; $data['published_timestamp'] = time(); $this->object->save($data);
The content of the $data variable was indeed saved in the database:
sqlite> select * from BlogPosts; First Post Title|Some cool content for the first post|1345665216
Characterization Tests
Inheritance is the strongest type of dependency.
A characterization test describes and verifies the current behavior of preexisting code. It is most frequently used to characterize legacy code, and it makes refactoring that code much easier.
A characterization test can test a module, a unit, or go all the way from the UI to the database; it all depends on what we want to test. In our case, such a test should exercise the controller and verify the contents of the database. This is not a typical unit, functional, or integration test, and it usually cannot be associated with either of those testing levels.
Characterization tests are a temporary safety net, and we typically delete them after the code is properly refactored and unit tested. Here is an implementation of a test, placed in the Test folder:
require_once '../BlogPostController.php';
class BlogPostControllerTest extends PHPUnit_Framework_TestCase {
private $object;
private $dbhandle;
function setUp() {
$this->object = new BlogPostController;
$this->dbhandle = new SQLite3('../Data/MyBlog');
}
function testSave() {
$this->cleanUPDatabase();
$data['title'] = 'First Post Title';
$data['content'] = 'Some cool content for the first post';
$data['published_timestamp'] = time();
$this->object->save($data);
$this->assertEquals($data, $this->getPostsFromDB());
}
private function cleanUPDatabase() {
$this->dbhandle->exec('DELETE FROM BlogPosts');
}
private function getPostsFromDB() {
$result = $this->dbhandle->query('SELECT * FROM BlogPosts');
return $result->fetchArray(SQLITE3_ASSOC);
}
}
This test creates a new controller object and executes its save() method. The test then reads the information from the database and compares it with the predefined $data[] array. We preform this comparison by using the $this->assertEquals() method, an assertion that presumes that its parameters are equal. If they are different, the test fails. Also, we clean the BlogPosts database table each time we run the test.
Legacy code is untested code. - Michael Feathers
With our test up and running, let's clean a little of the code. Open the database with the whole directory name and use sprintf() to compose the query string. This results in much simpler code:
class BlogPostController {
function save($data) {
$dbhandle = new SQLite3(__DIR__ . '/Data/MyBlog');
$query = sprintf('INSERT INTO BlogPosts VALUES ("%s","%s","%s")', $data['title'], $data['content'], time());
$dbhandle->exec($query);
}
}
The Table Data Gateway Pattern
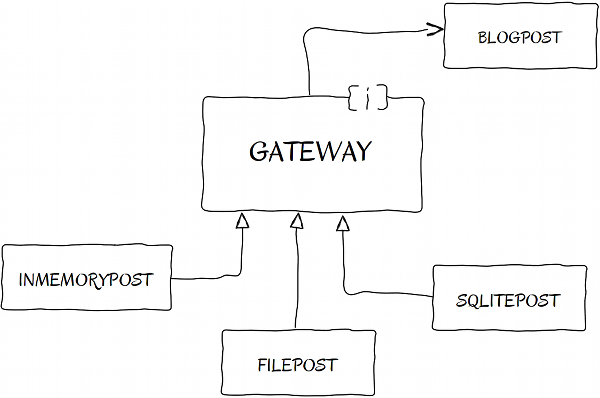
We recognize that our code needs to be moved from the controller to the business logic and persistence layer, and the Gateway Pattern can help us get started down that path. Here is the revised testSave() method:
function testItCanPersistABlogPost() {
$data = array('title' => 'First Post Title', 'content' => 'Some content.', 'timestamp' => time());
$blogPost = new BlogPost($data['title'], $data['content'], $data['timestamp']);
$mockedPersistence = $this->getMock('SqlitePost');
$mockedPersistence->expects($this->once())->method('persist')->with($blogPost);
$controller = new BlogPostController($mockedPersistence);
$controller->save($data);
}
This represents how we want to use the save() method on the controller. We expect the controller to call a method named persist($blogPostObject) on the gateway object. Let's change our BlogPostController to do that:
class BlogPostController {
private $gateway;
function __construct(Gateway $gateway = null) {
$this->gateway = $gateway ? : new SqlitePost();
}
function save($data) {
$this->gateway->persist(new BlogPost($data['title'], $data['content'], $data['timestamp']));
}
}
A good high level design has a well isolated business logic.
Nice! Our BlogPostController became much simpler. It uses the gateway (either supplied or instantiated) to persist the data by calling its persist() method. There is absolutely no knowledge about how the data is persisted; the persistence logic became modular.
In the previous test, we created the controller with a mock persistence object, ensuring that data never gets written to the database when running the test. In production code, the controller creates its own persisting object to persist the data using a SqlitePost object. A mock is an object that acts like its real counterpart, but it doesn't execute the real code.
Now let's retrieve a blog post from the data store. It's just as easy as saving data, but please note that I refactored the test a bit.
require_once '../BlogPostController.php';
require_once '../BlogPost.php';
require_once '../SqlitePost.php';
class BlogPostControllerTest extends PHPUnit_Framework_TestCase {
private $mockedPersistence;
private $controller;
private $data;
function setUp() {
$this->mockedPersistence = $this->getMock('SqlitePost');
$this->controller = new BlogPostController($this->mockedPersistence);
$this->data = array('title' => 'First Post Title', 'content' => 'Some content.', 'timestamp' => time());
}
function testItCanPersistABlogPost() {
$blogPost = $this->aBlogPost();
$this->mockedPersistence->expects($this->once())->method('persist')->with($blogPost);
$this->controller->save($this->data);
}
function testItCanRetrievABlogPostByTitle() {
$expectedBlogpost = $this->aBlogPost();
$this->mockedPersistence->expects($this->once())
->method('findByTitle')->with($this->data['title'])
->will($this->returnValue($expectedBlogpost));
$this->assertEquals($expectedBlogpost, $this->controller->findByTitle($this->data['title']));
}
public function aBlogPost() {
return new BlogPost($this->data['title'], $this->data['content'], $this->data['timestamp']);
}
}
And the implementation in the BlogPostController is just a one statement method:
function findByTitle($title) {
return $this->gateway->findByTitle($title);
}
Isn't this cool? The BlogPost class is now part of the business logic (remember the high level design schema from above). The UI/MVC creates BlogPost objects and uses concrete Gateway implementations to persist the data. All dependencies point to the business logic.
There's only one step left: create a concrete implementation of Gateway. Following is the SqlitePost class:
require_once 'Gateway.php';
class SqlitePost implements Gateway {
private $dbhandle;
function __construct($dbhandle = null) {
$this->dbhandle = $dbhandle ? : new SQLite3(__DIR__ . '/Data/MyBlog');
}
public function persist(BlogPost $blogPost) {
$query = sprintf('INSERT INTO BlogPosts VALUES ("%s","%s","%s")', $blogPost->title, $blogPost->content, $blogPost->timestamp);
$this->dbhandle->exec($query);
}
public function findByTitle($title) {
$SqliteResult = $this->dbhandle->query(sprintf('SELECT * FROM BlogPosts WHERE title = "%s"', $title));
$blogPostAsString = $SqliteResult->fetchArray(SQLITE3_ASSOC);
return new BlogPost($blogPostAsString['title'], $blogPostAsString['content'], $blogPostAsString['timestamp']);
}
}
Note: The test for this implementation is also available in the source code, but, due to its complexity and length, I did not include it here.
Moving Toward the Active Record Pattern
Active Record is one of the most controversial patterns. Some embrace it (like Rails and CakePHP), and others avoid it. Many Object Relational Mapping (ORM) applications use this pattern to save objects in tables. Here is its schema:
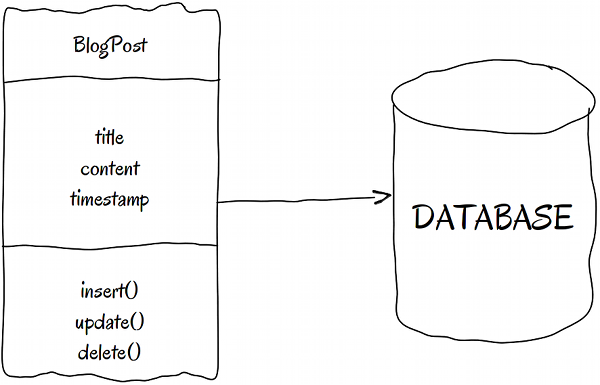
As you can see, Active Record-based objects can persist and retrieve themselves. This is usually achieved by extending an ActiveRecordBase class, a class that knows how to work with the database.
The biggest problem with Active Record is the extends dependency. As we all know, inheritance is the strongest type of dependency, and it's best to avoid it most of the time.
Before we go further, here is where we are right now:
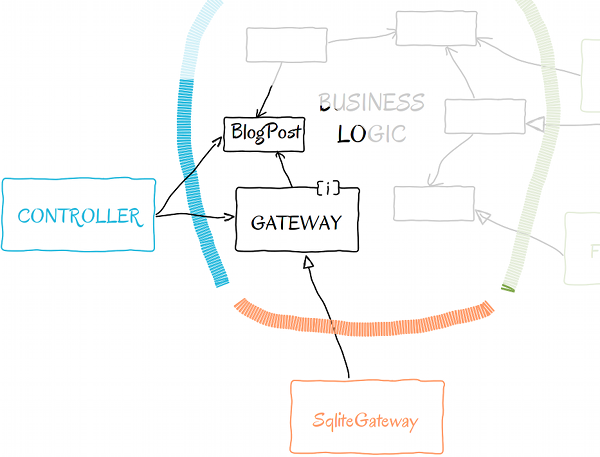
The gateway interface belongs to the business logic, and its concrete implementations belong to the persistence layer. Our BlogPostController has two dependencies, both pointing toward the business logic: the SqlitePost gateway and BlogPost class.
Going for Active Record
There are many other patterns, like the Proxy Pattern, that are closely related to persistence.
If we were to follow the Active Record pattern exactly as it is presented by Martin Fowler in his 2003 book, Patterns of Enterprise Application Architecture, then we would need to move the SQL queries into the BlogPost class. This, however, has the problem of violating both the Dependency Inversion Principle and the Open Closed Principle. The Dependency Inversion Principle states that:
- High-level modules should not depend on low-level modules. Both should depend on abstractions.
- Abstractions should not depend upon details. Details should depend upon abstractions.
And the Open Closed Principle states: software entities (classes, modules, functions, etc.) should be open for extension but closed for modification. We will take a more interesting approach and integrate the gateway into our Active Record solution.
If you try to do this on your own, you probably already realized that adding the Active Record pattern to the code will mess things up. For this reason, I took the option of disabling the controller and SqlitePost tests to concentrate only on the BlogPost class. The first steps are: make BlogPost load itself by setting its constructor as private and connect it to the gateway interface. Here is the first version of the BlogPostTest file:
require_once '../BlogPost.php';
require_once '../InMemoryPost.php';
require_once '../ActiveRecordBase.php';
class BlogPostTest extends PHPUnit_Framework_TestCase {
function testItCanConnectPostToGateway() {
$blogPost = BlogPost::load();
$blogPost->setGateway($this->inMemoryPost());
$this->assertEquals($blogPost->getGateway(), $this->inMemoryPost());
}
function testItCanCreateANewAndEmptyBlogPost() {
$blogPost = BlogPost::load();
$this->assertNull($blogPost->title);
$this->assertNull($blogPost->content);
$this->assertNull($blogPost->timestamp);
$this->assertInstanceOf('Gateway', $blogPost->getGateway());
}
private function inMemoryPost() {
return new InMemoryPost();
}
}
It tests that a blog post is correctly initialized and that it can have a gateway if set. It is a good practice to use multiple asserts when they all test the same concept and logic.
Our second test has several assertions, but all of them refer to the same common concept of empty blog post. Of course, the BlogPost class has also been modified:
class BlogPost {
private $title;
private $content;
private $timestamp;
private static $gateway;
private function __construct($title = null, $content = null, $timestamp = null) {
$this->title = $title;
$this->content = $content;
$this->timestamp = $timestamp;
}
function __get($name) {
return $this->$name;
}
function setGateway($gateway) {
self::$gateway = $gateway;
}
function getGateway() {
return self::$gateway;
}
static function load() {
if(!self::$gateway) self::$gateway = new SqlitePost();
return new self;
}
}
It now has a load() method that returns a new object with a valid gateway. From this point on, we will continue with the implementation of a load($title) method to create a new BlogPost with information from the database. For easy testing, I implemented an InMemoryPost class for persistence. It just keeps a list of objects in memory and returns information as desired:
class InMemoryPost implements Gateway {
private $blogPosts = array();
public function findByTitle($blogPostTitle) {
return array(
'title' => $this->blogPosts[$blogPostTitle]->title,
'content' => $this->blogPosts[$blogPostTitle]->content,
'timestamp' => $this->blogPosts[$blogPostTitle]->timestamp);
}
public function persist(BlogPost $blogPostObject) {
$this->blogPosts[$blogPostObject->title] = $blogPostObject;
}
}
Next, I realized that the initial idea of connecting the BlogPost to a gateway via a separate method was useless. So, I modified the tests, accordingly:
class BlogPostTest extends PHPUnit_Framework_TestCase {
function testItCanCreateANewAndEmptyBlogPost() {
$blogPost = BlogPost::load();
$this->assertNull($blogPost->title);
$this->assertNull($blogPost->content);
$this->assertNull($blogPost->timestamp);
}
function testItCanLoadABlogPostByTitle() {
$gateway = $this->inMemoryPost();
$aBlogPosWithData = $this->aBlogPostWithData($gateway);
$gateway->persist($aBlogPosWithData);
$this->assertEquals($aBlogPosWithData, BlogPost::load('some_title', null, null, $gateway));
}
private function inMemoryPost() {
return new InMemoryPost();
}
private function aBlogPostWithData($gateway = null) {
return BlogPost::load('some_title', 'some content', '123', $gateway);
}
}
As you can see, I radically changed the way BlogPost is used.
class BlogPost {
private $title;
private $content;
private $timestamp;
private function __construct($title = null, $content = null, $timestamp = null) {
$this->title = $title;
$this->content = $content;
$this->timestamp = $timestamp;
}
function __get($name) {
return $this->$name;
}
static function load($title = null, $content = null, $timestamp = null, $gateway = null) {
$gateway = $gateway ? : new SqlitePost();
if(!$content) {
$postArray = $gateway->findByTitle($title);
if ($postArray) return new self($postArray['title'], $postArray['content'], $postArray['timestamp']);
}
return new self($title, $content, $timestamp);
}
}
The load() method checks the $content parameter for a value and creates a new BlogPost if a value was supplied. If not, the method tries to find a blog post with the given title. If a post is found, it is returned; if there is none, the method creates an empty BlogPost object.
In order for this code to work, we will also need to change how the gateway works. Our implementation needs to return an associative array with title, content, and timestamp elements instead of the object itself. This is a convention I've chosen. You may find other variants, like a plain array, more attractive. Here are the modifications in SqlitePostTest:
function testItCanRetrieveABlogPostByItsTitle() {
[...]
//we expect an array instead of an object
$this->assertEquals($this->blogPostAsArray, $gateway->findByTitle($this->blogPostAsArray['title']));
}
private function aBlogPostWithValues() {
//we use static load instead of constructor call
return $blogPost = BlogPost::load(
$this->blogPostAsArray['title'],
$this->blogPostAsArray['content'],
$this->blogPostAsArray['timestamp']);
}
And the implementation changes are:
public function findByTitle($title) {
$SqliteResult = $this->dbhandle->query(sprintf('SELECT * FROM BlogPosts WHERE title = "%s"', $title));
//return the result directly, don't construct the object
return $SqliteResult->fetchArray(SQLITE3_ASSOC);
}
We are almost done. Add a persist() method to the BlogPost and call all the newly implemented methods from the controller. Here is the persist() method that will just use the gateway's persist() method:
private function persist() {
$this->gateway->persist($this);
}
And the controller:
class BlogPostController {
function save($data) {
$blogPost = BlogPost::load($data['title'], $data['content'], $data['timestamp']);
$blogPost->persist();
}
function findByTitle($title) {
return BlogPost::load($title);
}
}
The BlogPostController became so simple that I removed all of its tests. It simply calls the BlogPost object's persist() method. Naturally, you'll want to add tests if, and when, you have more code in the controller. The code download still contains a test file for the BlogPostController, but its content is commented.
Conclusion
This is just the tip of the iceberg.
You've seen two different persistence implementations: the Gateway and Active Record patterns. From this point, you can implement an ActiveRecordBase abstract class to extend for all your classes that need persistence. This abstract class can use different gateways in order to persist data, and each implementation can even use different logic to fit your needs.
But this is just the tip of the iceberg. There are many other patterns, such as the Proxy Pattern, which are closely related to persistence; each pattern works for a particular situation. I recommend that you always implement the simplest solution first, and then implement another pattern when your needs change.
I hope you enjoyed this tutorial, and I eagerly await your opinions and alternative implementations to my solution within the comments below.

Comments