In this last chapter we will look at the security aspects of HTTP, including how to identify users, how HTTP authentication works, and why some scenarios require HTTPS (secure HTTP). Along the way, we are also going to learn a bit about how to manage state with HTTP.
The Stateless (Yet Stateful) Web
HTTP is a stateless protocol, meaning each request-response transaction is independent of any previous or future transaction. There is nothing in the HTTP protocol that requires a server to retain information about an HTTP request. All the server needs to do is generate a response for every request. Every request will carry all the information a server needs to create the response.
The stateless nature of HTTP is one of the driving factors in the success of the web. The layered services we looked at in the previous chapter, services like caching, are all made possible (or at least easier) because every message contains all the information required to process the message. Proxy servers and web servers can inspect, transform, and cache messages. Without caching, the web couldn't scale to meet the demands of the Internet.
However, most of the web applications and services we build on top of HTTP are highly stateful.
A banking application will want a user to log in before allowing the user to view his or her account-related resources. As each stateless request arrives for a private resource, the application wants to ensure the user was already authenticated. Another example is when the user wants to open an account and fills out forms in a three-page wizard. The application will want to make sure the first page of the wizard is complete before allowing the user to submit the second page.
Fortunately, there are many options for storing state in a web application. One approach is to embed state in the resources being transferred to the client, so that all the state required by the application will travel back on the next request. This approach typically requires some hidden input fields and works best for short-lived state (like the state required for moving through a three-page wizard). Embedding state in the resource keeps all the state inside of HTTP messages, so it is a highly scalable approach, but it can complicate the application programming.
Another option is to store the state on the server (or behind the server). This option is required for state that has to be around a long time. Let's say the user submits a form to change his or her email address. The email address must always be associated with the user, so the application can take the new address, validate the address, and store the address in a database, a file, or call a web service to let someone else take care of saving the address.
For server-side storage, many web development frameworks like ASP.NET also provide access to a "user session". The session may live in memory, or in a database, but a developer can store information in the session and retrieve the information on every subsequent request. Data stored in a session is scoped to an individual user (actually, to the user's browsing session), and is not shared among multiple users.
Session storage has an easy programming model and is only good for short-lived state, because eventually the server has to assume the user has left the site or closed the browser and the server will discard the session. Session storage, if stored in memory, can negatively impact scalability because subsequent requests must go to the exact same server where the session data resides. Some load balancers help to support this scenario by implementing "sticky sessions".
You might be wondering how a server can track a user to implement session state. If two requests arrive at a server, how does the server know if these are two requests from the same user, or if there are two different users each making a single request?
In the early days of the web, server software might have differentiated users by looking at the IP address of a request message. These days, however, many users live behind devices using Network Address Translation, and for this and other reasons you can have multiple users effectively on the same IP address. An IP address is not a reliable technique for differentiating users.
Fortunately, there are more reliable techniques.
Identification and Cookies
Websites that want to track users will often turn to cookies. Cookies are defined by RFC6265 (http://tools.ietf.org/html/rfc6265), and this RFC is aptly titled "HTTP State Management Mechanism". When a user first visits a website, the site can give the user's browser a cookie using an HTTP header. The browser then knows to send the cookie in the headers of every additional request it sends to the site. Assuming the website has placed some sort of unique identifier into the cookie, then the site can now track a user as he or she makes requests, and differentiate one user from another.
Before we get into more details of what cookies look like and how they behave, it's worth noting a couple limitations. First, cookies can identify users in the sense that your cookie is different than my cookie, but cookies do not authenticate users. An authenticated user has proved his or her identity usually by providing credentials like a username and password. The cookies we are talking about so far just give us some unique identifier to differentiate one user from another, and track a user as requests are made to the site.
Secondly, since cookies can track what a user is doing, they raise privacy concerns in some circles. Some users will disable cookies in their browsers, meaning the browser will reject any cookies a server sends in a response. Disabled cookies present a problem for sites that need to track users, of course, and the alternatives are messy. For example, one approach to "cookieless sessions" is to place the user identifier into the URL. Cookieless sessions require that each URL a site gives to a user contains the proper identifier, and the URLs become much larger (which is why this technique is often called the "fat URL" technique).
Setting Cookies
When a website wants to give a user a cookie, it uses a Set-Cookie header in an HTTP response.
HTTP/1.1 200 OK
Content-Type: text/html; charset=utf-8
Set-Cookie: fname=Scott$lname=Allen;
domain=.mywebsite.com; path=/
...
There are three areas of information in the cookie shown in this sample. The three areas are delimited by semicolons (;). First, there are one or more name-value pairs. These name-value pairs are delimited by a dollar sign ($), and look very similar to how query parameters are formatted into a URL. In the example cookie, the server wanted to store the user's first name and last name in the cookie. The second and third areas are the domain and path, respectively. We'll circle back later to talk about domain and path.
A website can put any information it likes into a cookie, although there is a size limitation of 4 KB. However, many websites only put in a unique identifier for a user, perhaps a GUID. A server can never trust anything stored on the client unless it is cryptographically secured. Yes, it is possible to store encrypted data in a cookie, but it's usually easier to store an ID.
HTTP/1.1 200 OK
Set-Cookie: GUID=00a48b7f6a4946a8adf593373e53347c;
domain=.msn.com; path=/
Assuming the browser is configured to accept cookies, the browser will send the cookie to the server in every subsequent HTTP request.
GET ... HTTP/1.1 Cookie: GUID=00a48b7f6a4946a8adf593373e53347c; ...
When the ID arrives, the server software can quickly look up any associated user data from an in-memory data structure, database, or distributed cache. You can configure most web application frameworks to manipulate cookies and automatically look up session state. For example, in ASP.NET, the Session object exposes an easy API for reading and writing a user's session state. As developers, we never have to worry about sending a Set-Cookie header, or reading incoming cookies to find the associated session state. Behind the scenes, ASP.NET will manage the session cookie.
Session["firstName"] = "Scott"; // writing session state ... var lastName = Session["lastName"]; // reading session state
Again, it's worth pointing out that the firstName and lastName data stored in the session object is not going into the cookie. The cookie only contains a session identifier. The values associated with the session identifier are safe on the server. By default, the session data goes into an in-memory data structure and stays alive for 20 minutes. When a session cookie arrives in a request, ASP.NET will associate the correct session data with the Session object after finding the user's data using the ID stored in the cookie. If there is no incoming cookie with a session ID, ASP.NET will create one with a Set-Cookie header.
One security concern around session identifiers is how they can open up the possibility of someone hijacking another user's session. For example, if I use a tool like Fiddler to trace HTTP traffic, I might see a Set-Cookie header come from a server with SessionID=12 inside. I might guess that some other user already has a SessionID of 11, and create an HTTP request with that ID just to see if I can steal or view the HTML intended for some other user. To combat this problem, most web applications will use large random numbers as identifiers (ASP.NET uses 120 bits of randomness). An ASP.NET session identifier looks like the following, which makes it harder to guess what someone else's session ID would look like.
Set-Cookie: ASP.NET_SessionId=en5yl2yopwkdamv2ur5c3z45;
path=/; HttpOnly
HttpOnly Cookies
Another security concern around cookies is how vulnerable they are to a cross-site scripting attack (XSS). In an XSS attack, a malicious user injects malevolent JavaScript code into someone else's website. If the other website sends the malicious script to its users, the malicious script can modify, or inspect and steal cookie information (which can lead to session hijacking, or worse).
To combat this vulnerability, Microsoft introduced the HttpOnly flag (seen in the last Set-Cookie example). The HttpOnly flag tells the user agent to not allow script code to access the cookie. The cookie exists for "HTTP only"-i.e. to travel out in the header of every HTTP request message. Browsers that implement HttpOnly will not allow JavaScript to read or write the cookie on the client.
Types of Cookies
The cookies we've seen so far are session cookies. Session cookies exist for a single user session and are destroyed when the user closes the browser. Persistent cookies can outlive a single browsing session and a user agent will store the cookies to disk. You can shut down a computer and come back one week later, go to your favorite website, and a persistent cookie will still be there for the first request.
The only difference between the two is that a persistent a cookie needs an Expires value.
Set-Cookie: name=value; expires=Monday, 09-July-2012 21:12:00 GMT
A session cookie can explicitly add a Discard attribute to a cookie, but without an Expires value, the user agent should discard the cookie in any case.
Cookie Paths and Domains
So far we've said that once a cookie is set by a website, the cookie will travel to the website with every subsequent request (assuming the cookie hasn't expired). However, not all cookies travel to every website. The only cookies a user agent should send to a site are the cookies given to the user agent by the same site. It wouldn't make sense for cookies from amazon.com to be in an HTTP request to google.com. This type of behavior could only open up additional security and privacy concerns. If you set a cookie in a response to a request to www.server.com, the resulting cookie will only travel in the requests to www.server.com.
A web application can also change the scope of a cookie to restrict the cookie to a specific host or domain, and even to a specific resource path. The web application controls the scope using the domain and path attributes.
HTTP/1.1 200 OK Set-Cookie: name=value; domain=.server.com; path=/stuff ...
The domain attribute allows a cookie to span sub-domains. In other words, if you set a cookie from www.server.com, the user agent will only deliver the cookie to www.server.com. The domain in the previous example also permits the cookie to travel to any URL in the server.com domain, including images.server.com, help.server.com, and just plain server.com. You cannot use the domain attribute to span domains, so setting the domain to .microsoft.com in a response to .server.com is not legal and the user agent should reject the cookie.
The path attribute can restrict a cookie to a specific resource path. In the previous example, the cookie will only travel to a server.com site when the request URL is pointing to /stuff, or a location underneath /stuff, like /stuff/images. Path settings can help to organize cookies when multiple teams are building web applications in different paths.
Cookie Downsides
Cookies allow websites to store information in the client and the information will travel back to the sites in subsequent requests. The benefits to web development are tremendous, because cookies allow us to keep track of which request belongs to which user. But, cookies do have some problems which we've already touched on.
Cookies have been vulnerable to XSS attacks as we've mentioned earlier, and also receive bad publicity when sites (particularly advertising sites) use third-party cookies to track users across the Internet. Third-party cookies are cookies that get set from a different domain than the domain in the browser's address bar. Third-party cookies have this opportunity because many websites, when sending a page resource back to the client, will include links to scripts or images from other URLs. The requests that go to the other URLs allow the other sites to set cookies.
As an example, the home page at server.com can include a <script> tag with a source set to bigadvertising.com. This allows bigadvertising.com to deliver a cookie while the user is viewing content from server.com. The cookie can only go back to bigadvertising.com, but if enough websites use bigadvertising.com, then Big Advertising can start to profile individual users and the sites they visit. Most web browsers will allow you to disable third-party cookies (but they are enabled by default).
Two of the biggest downsides to cookies, however, are how they interfere with caching and how they transmit data with every request. Any response with a Set-Cookie header should not be cached, at least not the headers, since this can interfere with user identification and create security problems. Also, keep in mind that anything stored in a cookie is visible as it travels across the network (and in the case of a persistent cookie, as it sits on the file system). Since we know there are lots of devices that can listen and interpret HTTP traffic, a cookie should never store sensitive information. Even session identifiers are risky, because if someone can intercept another user's ID, he or she can steal the session data from the server.
Even with all these downsides, cookies are not going away. Sometimes we need state to travel over HTTP, and cookies offer this capability in an easy, mostly transparent manner. Another capability we sometimes need is the ability to authenticate the user. We'll discuss authentication features next.
Authentication
The process of authentication forces a user to prove her or his identity by entering a username and password, or an email and a PIN, or some other type of credentials.
At the network level, authentication typically follows a challenge/response format. The client will request a secure resource, and the server will challenge the client to authenticate. The client then needs to send another request and include authentication credentials for the server to validate. If the credentials are good, the request will succeed.
The extensibility of HTTP allows HTTP to support various authentication protocols. In this section we'll briefly look at the top 5: basic, digest, Windows, forms, and OpenID. Of these five, only two are "official" in the HTTP specification-the basic and digest authentication protocols. We'll look at these two first.
Basic Authentication
With basic authentication, the client will first request a resource with a normal HTTP message.
GET http://localhost/html5/ HTTP/1.1 Host: localhost
Web servers will let you configure access to specific files and directories. You can allow access to all anonymous users, or restrict access so that only specific users or groups can access a file or directory. For the previous request, let's imagine the server is configured to only allow certain users to view the /html5/ resource. In that case, the server will issue an authentication challenge.
HTTP/1.1 401 Unauthorized WWW-Authenticate: Basic realm="localhost"
The 401 status code tells the client the request is unauthorized. The WWW-Authenticate header tells the client to collect the user credentials and try again. The realm attribute gives the user agent a string it can use as a description for the protected area. What happens next depends on the user agent, but most browsers can display a UI for the user to enter credentials.
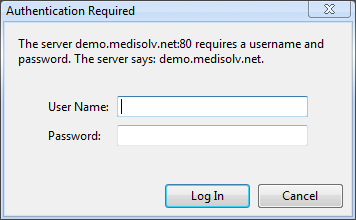
With the credentials in hand, the browser can send another request to the server. This request will include an Authorization header.
GET http://localhost/html5/ HTTP/1.1 Authorization: Basic bm86aXdvdWxkbnRkb3RoYXQh
The value of the authorization header is the client's username and password in a base 64 encoding. Basic authentication is insecure by default, because anyone with a base 64 decoder who can view the message can steal a user's password. For this reason, basic authentication is rarely used without using secure HTTP, which we'll look at later.
It's up to the server to decode the authorization header and verify the username and password with the operating system, or whatever credential management system is on the server. If the credentials match, the server can make a normal reply. If the credentials don't match, the server should respond with a 401 status again.
Digest Authentication
Digest authentication is an improvement over basic authentication because it does not transmit user passwords using base 64 encoding (which is essentially transmitting the password in plain text). Instead, the client must send a digest of the password. The client computes the digest using the MD5 hashing algorithm with a nonce the server provides during the authentication challenge (a nonce is a cryptographic number used to help prevent replay attacks).
The digest challenge response is similar to the basic authentication challenge response, but with additional values coming from the server in the WWW-Authenticate header for use in the cryptographic functions.
HTTP/1.0 401 Unauthorized
WWW-Authenticate: Digest realm="localhost",
qop="auth,auth-int",
nonce="dcd98b7102dd2f0e8b11d0f600bfb0c093",
opaque="5ccc069c403ebaf9f0171e9517f40e41"
Digest authentication is better than basic authentication when secure HTTP is not available, but it is still far from perfect. Digest authentication is still vulnerable to man-in-the-middle attacks in which someone is sniffing network traffic.
Windows Authentication
Windows Integrated Authentication is not a standard authentication protocol but it is popular among Microsoft products and servers. Although Windows Authentication is supported by many modern browsers (not just Internet Explorer), it doesn't work well over the Internet or where proxy servers reside. You'll find it is common on internal and intranet websites where a Microsoft Active Directory server exists.
Windows Authentication depends on the underlying authentication protocols supported by Windows, including NTLM and Kerberos. The Windows Authentication challenge/response steps are very similar to what we've seen already, but the server will specify NTLM or Negotiate in the WWW-Authenticate header (Negotiate is a protocol that allows the client to select Kerberos or HTML).
HTTP/1.1 401 Unauthorized WWW-Authenticate: Negotiate
Windows Authentication has the advantage of being secure even without using secure HTTP, and of being unobtrusive for users of Internet Explorer. IE will automatically authenticate a user when challenged by a server, and will do so using the user's credentials that he or she used to log into the Windows operating system.
Forms-Based Authentication
Forms authentication is the most popular approach to user authentication over the Internet. Forms-based authentication is not a standard authentication protocol and doesn't use WWW-Authenticate or Authorization headers. However, many web application frameworks provide some out of the box support for forms-based authentication.
With forms-based authentication, an application will respond to a request for a secure resource by an anonymous user by redirecting the user to a login page. The redirect is an HTTP 302 temporary redirect. Generally, the URL the user is requesting might be included in the query string of the redirect location so that once the user has completed the login, the application can redirect the user to the secure resource he or she was trying to reach.
HTTP/1.1 302 Found Location: /Login.aspx?ReturnUrl=/Admin.aspx
The login page for forms-based authentication is an HTML form with inputs for the user to enter credentials. When the user clicks submit, the form values will POST to a destination where the application needs to take the credentials and validate them against a database record or operating system.
<form method="post">
...
<input type="text" name="username" />
<input type="password" name="password" />
<input type="submit" value="Login" />
</form>
Note that forms-based authentication will transmit a user's credentials in plain text, so like basic authentication, forms-based authentication is not secure unless you use secure HTTP. In response to the POST message with credentials (assuming the credentials are good), the application will typically redirect the user back to the secure resource and also set a cookie indicating the user is now authenticated.
HTTP/1.1 302 Found Location: /admin.aspx Set-Cookie: .ASPXAUTH=9694BAB... path=/; HttpOnly
For ASP.NET, the authentication ticket (the .ASPXAUTH cookie value) is encrypted and hashed to prevent tampering. However, without secure HTTP the cookie is vulnerable to being intercepted, so session hijacking is still a potential problem. Yet, forms authentication remains popular because it allows applications complete control over the login experience and credential validation.
OpenID
While forms-based authentication gives an application total control over user authentication, many applications don't want this level of control. Specifically, applications don't want to manage and verify usernames and passwords (and users don't want to have a different username and password for every website). OpenID is an open standard for decentralized authentication. With OpenID, a user registers with an OpenID identity provider, and the identity provider is the only site that needs to store and validate user credentials. There are many OpenID providers around, including Google, Yahoo, and Verisign.
When an application needs to authenticate a user, it works with the user and the user's identity provider. The user ultimately has to verify his or her username and password with the identity provider, but the application will know if the authentication is successful thanks to the presence of cryptographic tokens and secrets. Google has an overview of the process on its "Federated Login for Google Account Users" webpage (https://developers.google.com/accounts/docs/OpenID).
While OpenID offers many potential benefits compared to forms authentication, it has faced a lack of adoption due to complexity in implementing, debugging, and maintaining the OpenID login dance. We have to hope the toolkits and frameworks continue to evolve to make the OpenID approach to authentication easier.
Secure HTTP
Previously we mentioned how the self-describing textual HTTP messages are one of the strengths of the web. Anyone can read a message and understand what's inside. But, there are many messages we send over the web that we don't want anyone else to see. We've discussed some of those scenarios in this book. We don't want anyone else on the network to see our passwords, for example, but we also don't want them to see our credit card numbers or bank account numbers. Secure HTTP solves this problem by encrypting messages before the messages start traveling across the network.
Secure HTTP is also known as HTTPS (because it uses an https scheme in the URL instead of a regular http scheme). The default port for HTTP is port 80, and the default port for HTTPS is port 443. The browser will connect to the proper port depending on the scheme (unless it has to use an explicit port that is present in the URL). HTTPS works by using an additional security layer in the network protocol stack. The security layer exists between the HTTP and TCP layers, and features the use of the Transport Layer Security protocol (TLS) or the TLS predecessor known as Secure Sockets Layer (SSL).
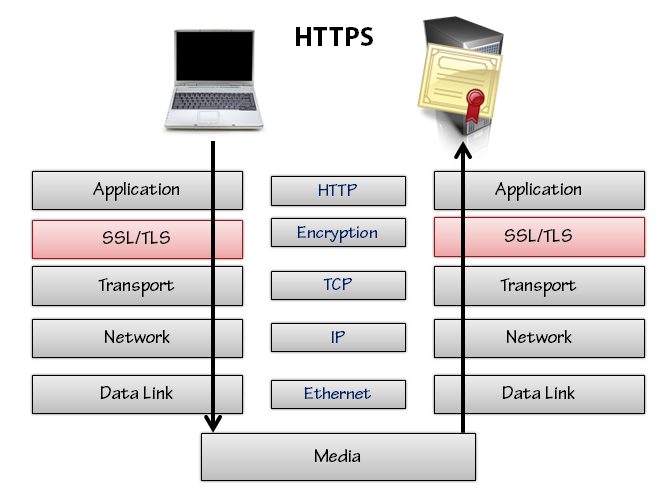
HTTPS requires a server to have a cryptographic certificate. The certificate is sent to the client during setup of the HTTPS communication. The certificate includes the server's host name, and a user agent can use the certificate to validate that it is truly talking to the server it thinks it is talking to. The validation is all made possible using public key cryptography and the existence of certificate authorities, like Verisign, that will sign and vouch for the integrity of a certificate. Administrators have to purchase and install certificates from the certificate authorities.
There are many cryptographic details we could cover, but from a developer's perspective, the most important things to know about HTTPS are:
- All traffic over HTTPS is encrypted in the request and response, including the HTTP headers and message body, and also everything after the host name in the URL. This means the path and query string data are encrypted, as well as all cookies. HTTPS prevents session hijacking because no eavesdroppers can inspect a message and steal a cookie.
- The server is authenticated to the client thanks to the server certificate. If you are talking to mybigbank.com over HTTPS, you can be sure your messages are really going to mybigbank.com and not someone who stuck a proxy server on the network to intercept requests and spoof response traffic from mybigbank.com
- HTTPS does not authenticate the client. Applications still need to implement forms authentication or one of the other authentication protocols mentioned previously if they need to know the user's identity. HTTPS does make forms-based authentication and basic authentication more secure since all data is encrypted. There is the possibility of using client-side certificates with HTTPS, and client-side certificates would authenticate the client in the most secure manner possible. However, client-side certificates are generally not used on the open Internet since not many users will purchase and install a personal certificate. Corporations might require client certificates for employees to access corporate servers, but in this case the corporation can act as a certificate authority and issue employees certificates they create and manage.
HTTPS does have some downsides and most of them are related to performance. HTTPS is computationally expensive, and large sites often use specialized hardware (SSL accelerators) to take the cryptographic computation load off the web servers. HTTPS traffic is also impossible to cache in a public cache, but user agents might keep HTTPS responses in their private cache. Finally, HTTPS connections are expensive to set up and require an additional handshake between the client and server to exchange cryptographic keys and ensure everyone is communicating with the proper secure protocol. Persistent connections can help to amortize this cost.
In the end, if you need secure communications you'll willingly pay the performance penalties.
Where Are We?
In this article we've looked at cookies, authentication, and secure HTTP. If you've completed this entire session, I hope you've found some valuable information that will help you as you write, maintain, and debug web applications.

Comments