Declaration vs. Definition
Tip: This first section, “Declaration vs. Definition,” is a bit dense. Understanding these concepts before looking at a sample will help you understand the sample. In turn, looking at a sample will help you understand these concepts. I recommend you read this and then look through the samples in the next two sections. If parts of this section weren’t clear, come back to reread this section.
In C#, classes and other types are declared and defined at the same time. Even with the partial keyword, the class definition is simply allowed to spread over multiple files; it does not change the combination of declaration and definition. The only exception to this rule is when doing interop (which uses DllImportAttribute and the extern keyword to declare a function defined in an external DLL). In that case, the definition isn’t in C# but is almost certainly in some non-.NET library. (If the DLL was a .NET assembly, you could just add a reference to it and use it without any interop code being necessary.)
I write this because in C++, declaration and definition can usually be separated, and frequently are. It is common to see a class declared in a header file (which, by convention, has a .H suffix) and defined in a source file (which, by convention, has a .CPP suffix). This is true not just for classes, but also for stand-alone functions and even structures and unions when they have member functions associated with them.
Expect to see one or more #include "SomeHeader.h" lines at the top of a .CPP file. These statements tell the compiler (or, more accurately, the preprocessor) that there are declarations and possibly definitions in that file, or in files included from it, that are necessary for the compiler to make sense of parts of the C++ code that follows.
With Visual C++, when including a header that is part of your project or is not found in the build system’s include path, use the #include "HeaderFile.h" syntax. When including a system include file, such as Windows.h, use the #include <Windows.h> syntax. Lastly, when including an include file that is part of the C++ Standard Library (which we will discuss in more detail later), use the #include <vector> syntax (i.e. no .h is included). The meaning of the " " versus the < > syntax for including files is implementation-defined, though both GCC and Visual C++ use quoted syntax for local header files and bracketed syntax for system header files.
Note: The reason the .H suffix was left off from the C++ Standard Library include files was to avoid naming collisions with C++ compilers that already provided header files that used those names when the C++ Standard Library was introduced. They are normal header files, have no fear.
To understand why the difference between declaration and definition matters in C++, it’s important to have a basic understanding of the C++ build process. Here’s what generally happens:
- The preprocessor examines a source file, inserts the text of the files specified by the include statements (and the text of the files specified by their include statements, etc.), and also evaluates and acts on any other preprocessor directives (e.g., expanding macros) and any pragma directives.
- The compiler takes the output from the preprocessor and compiles that code into machine code, which it stores, along with other information needed for the linking phase, in an OBJ file.
Steps 1 and 2 are repeated for each source file within the project. - Steps 1 and 2 are repeated for each source file within the project.
- The linker examines the output files from the compiler and the library files that your project links. It finds all of the places where the compiler identified something as being declared but not defined within that particular source file. It then locates the appropriate address for the definition and patches that address in.
- Once everything has been linked successfully, the linker binds everything together and outputs the finished product (typically either an executable program or a library file).
An error during any of those phases will stop the build process, of course, and the previous description is only a rough sketch of the Visual C++ build chain. Compiler authors have some flexibility in exactly how they do things. For example, there’s no requirement that any intermediate files be produced, so in theory, the whole build process could be done in memory, though in practice, I doubt anyone would ever do that. So consider that list as just a rough outline, not an exact description.
I’ve been referring to everything as source files to keep the terminology simple. Within the C++ standard, these combinations of a source file plus all of its include files is referred to as a compilation unit. I mention that now only because I will be using the term a bit further along. Let’s consider the three build phases in turn.
The preprocessor doesn’t care about C++ declarations and definitions. Indeed, it doesn’t even care if your program is in C++. The only business it has with your source files is to take care of all lines that begin with a #, thus marking them as preprocessor directives. As long as those lines are properly formed, and it can find all of the included files, if any, the preprocessor will do its work, adding and removing text as directed. It will pass the results on to the compiler, typically without writing its result out to a file since compilation immediately follows preprocessing.
The compiler does care about declarations and definitions and very much is concerned with whether your program is valid C++ code or not. However, it doesn’t need to know what a function does when it comes across it. It just needs to know what the function signature is—such as int AddTwoNumbers(int, int);.
The same is true for classes, structures, and unions; as long as the compiler knows the declaration (or in the case of a pointer, simply that the particular token is a class, a structure, a union, or an enum), then it doesn’t need any definitions. With just the declaration, it knows if your call to AddTwoNumbers is syntactically correct and that the class Vehicle; is in fact a class, so it can create a pointer to it when it sees Vehicle* v;, which is all it cares about.
The linker does care about definitions. Specifically, it cares that there is one, and only one, definition matching each of the declarations in your project. The lone exception is inline functions, which end up being created in each compilation unit in which they are used. However, they are created in a way that avoids any issues with multiple definitions.
You can have duplicate declarations among the compilation units for your program; doing so is a common trick for improving build times, as long as only one definition matches a declaration (except for inlines). In order to ensure this one definition rule is met, C++ compilers tend to use something called name mangling.
This ensures each declaration is matched up with its proper definition, including issues such as overloaded functions and namespaces (which allow the same name to be reused if the uses are in different namespaces), and class, structure, union, and enum definitions nested within classes, structures, or unions.
This name mangling is what results in terrifying linker errors, which we will see an example of in the “Inline Member Functions” section.
The severability of declarations from definitions lets you build your C++ projects without recompiling each source file every time. It also lets you build projects that use libraries for which you do not have the source code. There are, of course, other ways to accomplish those goals (C# uses a different build process for instance). This is the way C++ does it; understanding that basic flow helps make sense of many peculiarities in C++ that you do not encounter in C#.
Functions
There are two types of functions in C++: stand-alone functions and member functions. The main difference between them is that a member function belongs to a class, structure, or union, whereas a stand-alone function does not.
Stand-alone functions are the most basic types of functions. They can be declared in namespaces, they can be overloaded, and they can be inline. Let’s look at a few.
Sample: FunctionsSample\Utility.h
#pragma once
namespace Utility
{
inline bool IsEven(int value)
{
return (value % 2) == 0;
}
inline bool IsEven(long long value)
{
return (value % 2) == 0;
}
void PrintIsEvenResult(int value);
void PrintIsEvenResult(long long value);
void PrintBool(bool value);
}
Sample: FunctionsSample\Utility.cpp
#include "Utility.h"
#include <iostream>
#include <ostream>
using namespace std;
using namespace Utility;
void Utility::PrintIsEvenResult(int value)
{
wcout << L"The number " << value << L" is " <<
(IsEven(value) ? L"" : L"not ") << L"even."
<< endl;
}
void Utility::PrintIsEvenResult(long long value)
{
wcout << L"The number " << value << L" is " <<
(IsEven(value) ? L"" : L"not ") << L"even."
<< endl;
}
void Utility::PrintBool(bool value)
{
wcout << L"The value is" <<
(value ? L"true." : L"false.") << endl;
}
Sample: FunctionsSample\FunctionsSample.cpp
#include "Utility.h"
#include "../pchar.h"
using namespace Utility;
int _pmain(int /*argc*/, _pchar* /*argv*/[])
{
int i1 = 3;
int i2 = 4;
long long ll1 = 6;
long long ll2 = 7;
bool b1 = IsEven(i1);
PrintBool(b1);
PrintIsEvenResult(i1);
PrintIsEvenResult(i2);
PrintIsEvenResult(ll1);
PrintIsEvenResult(ll2);
return 0;
}
The header file Utility.h declares and defines two inline functions, both called IsEven (making IsEven an overloaded function). It also declares three more functions: two called PrintIsEvenResult and one called PrintBool. The source file Utility.cpp defines these last three functions. Lastly, the source file FunctionsSample.cpp uses that code to create a simple program.
Any functions defined in a header file must be declared inline; otherwise, you’ll wind up with multiple definitions and a linker error. Also, function overloads need to be different by more than just their return type; otherwise, the compiler cannot make sure you are really getting the version of the method you wanted. C# is the same way, so this shouldn’t be anything new.
As seen in Utility.cpp, when you are defining a stand-alone function that is in a namespace, you need to put the namespace before the function name and separate it with the scope resolution operator. If you used nested namespaces, you include the whole namespace nesting chain—for example, void RootSpace::SubSpace::SubSubSpace::FunctionName(int param) { ... };.
Simple Class
The following sample includes a class broken into a header file and a source file.
Sample: SimpleClassSample\VehicleCondition.h
#pragma once
#include <string>
namespace Inventory
{
enum class VehicleCondition
{
Excellent = 1,
Good = 2,
Fair = 3,
Poor = 4
};
inline const std::wstring GetVehicleConditionString(
VehicleCondition condition
)
{
std::wstring conditionString;
switch (condition)
{
case Inventory::VehicleCondition::Excellent:
conditionString = L"Excellent";
break;
case Inventory::VehicleCondition::Good:
conditionString = L"Good";
break;
case Inventory::VehicleCondition::Fair:
conditionString = L"Fair";
break;
case Inventory::VehicleCondition::Poor:
conditionString = L"Poor";
break;
default:
conditionString = L"Unknown Condition";
break;
}
return conditionString;
}
}
Sample: SimpleClassSample\Vehicle.h
#pragma once
#include <string>
namespace Inventory
{
enum class VehicleCondition;
class Vehicle
{
public:
Vehicle(
VehicleCondition condition,
double pricePaid
);
~Vehicle(void);
VehicleCondition GetVehicleCondition(void)
{
return m_condition;
};
void SetVehicleCondition(VehicleCondition condition);
double GetBasis(void) { return m_basis; };
private:
VehicleCondition m_condition;
double m_basis;
};
}
Sample: SimpleClassSample\Vehicle.cpp
#include "Vehicle.h"
#include "VehicleCondition.h"
using namespace Inventory;
using namespace std;
Vehicle::Vehicle(VehicleCondition condition, double pricePaid) :
m_condition(condition),
m_basis(pricePaid)
{
}
Vehicle::~Vehicle(void)
{
}
void Vehicle::SetVehicleCondition(VehicleCondition condition)
{
m_condition = condition;
}
Sample: SimpleClassSample\SimpleClassSample.cpp
#include <iostream>
#include <ostream>
#include <string>
#include <iomanip>
#include "Vehicle.h"
#include "VehicleCondition.h"
#include "../pchar.h"
using namespace Inventory;
using namespace std;
int _pmain(int /*argc*/, _pchar* /*argv*/[])
{
auto vehicle = Vehicle(VehicleCondition::Excellent, 325844942.65);
auto condition = vehicle.GetVehicleCondition();
wcout << L"The vehicle is in " <<
GetVehicleConditionString(condition).c_str() <<
L" condition. Its basis is $" << setw(10) <<
setprecision(2) << setiosflags(ios::fixed) <<
vehicle.GetBasis() << L"." << endl;
return 0;
}
In Vehicle.h, we begin with a forward declaration of the VehicleCondition enum class. We will discuss this technique more at the end of the chapter. For now the key points are (1) that we could either use this forward declaration or include the VehicleCondition.h header file and (2) that the declaration of VehicleCondition must come before the class definition for Vehicle.
In order for the compiler to allot enough space for instances of Vehicle, it needs to know how large each data member of Vehicle is. We can let it know either by including the appropriate header file or, in certain circumstances, by using a forward declaration. If the declaration of VehicleCondition came after the definition of Vehicle, then the compiler would refuse to compile the code since the complier would not know how big VehicleCondition is or even what type of data it is.
In that case, a simple declaration suffices to tell the compiler what VehicleCondition is (an enum class) and how big it is. Enum classes default to using an int as their backing field unless otherwise specified. If we leave the backing field blank, but then say to use a short, or a long, or some other backing field type somewhere else, the compiler would generate a different error message, telling us we have multiple, conflicting declarations.
We then proceed to define the Vehicle class. The definition includes the declaration of its member functions and its member variables. For the most part, we do not define the member functions. The exceptions are the GetVehicleCondition member function and the GetBasis member function, which we will discuss in the “Inline Member Functions” section.
We define the other member functions of Vehicle in Vehicle.cpp. In this case, the member functions are the constructor, the destructor, and SetVehicleCondition. Typically, a function like SetVehicleCondition would be inline, so would simple constructors and destructors in the Vehicle class. They are defined separately here to illustrate how you define these types of member functions when they are not inline functions. We will discuss the odd-looking constructor syntax in the chapter devoted to constructors. The rest of the Vehicle class code should be clear.
Note: Although you are not required to adopt the ClassName.h or ClassName.cpp file naming convention, you will see it in use almost everywhere because it makes using and maintaining code easier.
The GetVehicleConditionString inline function in VehicleCondition.h returns a copy of the std::wstring created in that function, not the local value itself. Coming from C#, you might think this a bit odd without having a new keyword used. We will explore this when we discuss the automatic duration type in the chapter on storage duration.
The entry point function uses some of the C++ Standard Library’s I/O formatting functionality.
Member Functions
As discussed earlier, member functions are part of a class, structure, or union. Simply, I will talk about them as class members from here on.
Static member functions can call other static class member functions, regardless of protection level. Static member functions can also access static class member data either explicitly (i.e. SomeClass::SomeFloat = 20.0f;) or implicitly (i.e. SomeFloat = 20.0f;), regardless of protection level.
The explicit form is helpful if you have a parameter with the same name as a class member. Prefixing member data with an m_, such as m_SomeFloat, eliminates that problem and makes it clear when you are working with class member data versus local variables or parameters. That’s just a style choice, not a requirement.
Instance (i.e. non-static) member functions are automatically assigned a this pointer to the instance data for the instance on which they were called. Instance member functions can call other class member functions and access all class member data either explicitly—the same as static members using this->m_count++; for instance data—or implicitly—the same as static and instance data (e.g., m_data++;), regardless of protection level.
Inline Member Functions
In SampleClass\Vehicle.h, the GetVehicleCondition and GetBasis member functions are both declared and defined. This combination of declaration and definition is called an inline member function in C++. Since this is similar to writing methods in C#, it might be inviting to do so in C++ as well. With some exceptions, you shouldn’t do this.
As we discussed previously, when you build a C++ project, the compiler goes through each of your source files only once. It may make many passes at the same source files to optimize them, but it’s not going to come back again after it is finished.
In contrast, the compiler will come back to your header files every time they are included in another file, regardless of whether it’s a source file or another header file. This means the compiler can end up running through the code in the header files many, many times during a build.
At the beginning of the SampleClass\Vehicle.h header file, you see the #pragma once directive. This is a useful and important line. If you include the header file A.h in a source file and then include another header file that has A.h, the #pragma once directive would tell the preprocessor not to include the contents of A.h again. This prevents the preprocessor from bouncing back and forth between two header files that include each other indefinitely. It also prevents compiler errors. If A.h was included multiple times, the compiler would fail when it reached a type definition from the second inclusion of A.h.
Even with that directive, the compiler still needs to include and parse that header file code for each source file that includes it. The more things you put into your header file, the longer it takes to build each source file. This increases compilation time, which, as you will discover, can be quite lengthy with C++ projects when compared with C#.
When you do include a member function’s definition inline in the header file, the C++ compiler can make that code inline in any source file where that function is used. This typically results in faster program executions since, rather than needing to make a call to a function, the program can simply run the code in place.
Scope is preserved by the compiler, so you don’t need to worry about naming collisions between variables defined in the inline function and in a function where it is used. When dealing with code, such as the previous examples, where you are simply retrieving a member variable’s value, inline definitions can improve speed, especially if the code is executing within a loop.
There is an alternate way to define an inline member function. If you want to keep your class definitions nice and clean, with no member function definitions within them, but still want to have some inline member functions, you can do something like the following instead:
Sample: SimpleClassSample\Vehicle.h (alternate code commented out at the bottom of the file).
#pragma once
#include <string>
namespace Inventory
{
enum class VehicleCondition;
class Vehicle
{
public:
Vehicle(
VehicleCondition condition,
double pricePaid
);
~Vehicle(void);
inline VehicleCondition GetVehicleCondition(void);
void SetVehicleCondition(VehicleCondition condition);
inline double GetBasis(void);
private:
VehicleCondition m_condition;
double m_basis;
};
VehicleCondition Vehicle::GetVehicleCondition(void)
{
return m_condition;
}
double Vehicle::GetBasis(void)
{
return m_basis;
}
}
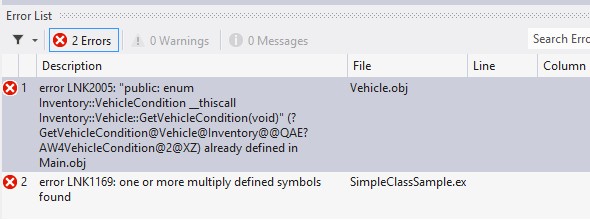
off of the Vehicle::GetVehicleCondition member function.
Linker errors are always horrible looking, by the way. The reason is that the linker no longer knows what your variables and functions were named in the source file. It only knows what the compiler transformed those names into in order to make all the names unique. This includes overload methods, which need a unique name at the linking stage so the linker can connect a call to an overloaded member function to the correct overload version of that function.
The errors in Figure 1 are simply telling us that we defined Inventory::Vehicle::GetVehicleCondition(void) more than once. Now, we know we only defined it once, just in the header file, but we have included the header file in both Vehicle.cpp and in Main.cpp in the SimpleClassSample project.
Since we intentionally forgot to add the inline keyword to the Vehicle::GetVehicleCondition function declaration, the compiler doesn’t make the code inline. Instead, it compiles it as a function in both Main.cpp and Vehicle.cpp.
This, of course, is something the compiler is fine with because it treats each source file as a unique compilation unit. The compiler doesn’t know any better, since, by the time the code reaches it, the code has already been inserted by the preprocessor stage. Only when the linker gets all the compiled code and tries to match everything up do we reach a phase where the build process says, “Hey, I already have another version of this function!” and then fails.
As you can see, there are two ways of making member functions inline. Both must be done within the header file since the compiler will evaluate the header-file code as many times as they are included, but it will only run through source files once. If you use the second method and forget an inline keyword, then you will have horrible linker errors. If you use the second method and remember the inline keyword, but define the functions within the source file, you will get horrible linker errors—this time saying there is no definition.
Tip: Don’t try to make everything inline. You will just end up with slow compile times that kill your productivity. Do inline things that make sense, like simple getter and setter functions for member variables. Like anything else, profile first, and then optimize if needed.
Protection Levels and Access Specifiers
Member functions and member data have three possible access specifiers:
- public
- protected
- private
These access specifiers denote the level of accessibility that the member has. In SampleClass\Vehicle.h, you can see two examples of how these are used. Note that unlike in C#, you do not restate the access specifier in front of each member. Instead, you state the access specifier, followed by a colon (e.g., public:), and then every declaration and definition that comes after is given that level of accessibility until you reach another access specifier.
By default, class members are private. This means if you have no access specifier at the beginning of the class declaration, then all members that are declared will be private until an access specifier is reached. If none is reached, you’d have an entirely private class, which would be very odd.
Structure members default to public, so on occasion you’ll see a structure without any access specifiers. If you wish to use them in a structure, though, they work the same as in a class.
Lastly, you can use the same access specifier more than once; if you want to organize your class so you define the member functions first and then the member variables (or vice versa), you could easily do something like this:
Note: This code is expository only; it is not included in any of the samples.
#include <string>
class SomeClass
{
public:
SomeClass(void);
virtual ~SomeClass(void);
int AddTwoInts(int, int);
void StoreAString(const wchar_t*);
private:
bool CheckForIntAdditionOverflow(int, int);
public:
int SomePublicInteger;
protected:
std::wstring m_storedString;
};
The previous class definition doesn’t define anything particularly useful. However, it does serve as an example of the use of all three access specifiers. It also demonstrates that you can use specifiers more than once, such as public in the previous example.
Inheritance
When specifying classes that your class derives from In C++, you should also specify an access specifier. If not, you will get the default access levels: private for a class and public for a structure. Note that I said classes. C++ supports multiple-inheritance. This means a class or structure can have more than one direct base class or structure, unlike C# where a class can have only one parent.
C++ does not have a separate interface type. In general, multiple-inheritance should be avoided except as a workaround for lack of a separate interface. In other words, a class should have only zero or one real base class along with zero or more purely abstract classes (interfaces). This is just a personal style recommendation, though.
There are some good arguments for multiple-inheritance. For instance, say you have three groups of functionality. Each one consists of functions and data. Then say each group is unrelated to the other—there’s no connection between them, but they aren’t mutually exclusive. In this case, you may wish to put each functionality group into its own class. Then if you have a situation where you want to create a class needing two of these groups, or even all three, you can simply create a class that inherits from all three, and you’re done.
Or, you’re done as long as you didn’t have any naming conflicts in your public and protected members’ functions and variables. For example, what if all three of the functionality groups have a member function void PrintDiagnostics(void);? You’d be doomed, yes? Well, it turns out that no, you are not doomed (usually). You need to use some weird syntax to specify which base class’ PrintDiagnostics function you want. And even then you aren’t quite done.
C++ lets you specify whether you want a class to be a plain base class or a virtual base class. You do this by putting or not putting the keyword virtual before the class’ name in the base class specifier. We’ll look at a sample shortly that addresses all of this, but before we do, it’s important to understand that if you inherit a class at least twice, and two or more of the inheritance’s are not virtual, you will end up with multiple copies of that class’ data members
This causes a whole bunch of problems when trying to specify which of those you wish to use. Seemingly, the solution is to derive from everything virtually, but that has a run-time performance hit associated with it due to how C++ implementations tend to resolve virtual members. Better still, try to avoid having this ever happen in the first place, but as that’s not always possible, do remember virtual inheritance.
And now a sample to help make this all make sense:
Sample: InheritanceSample\InheritanceSample.cpp
#include <iostream>
#include <ostream>
#include <string>
#include <typeinfo>
#include "../pchar.h"
using namespace std;
class A
{
public:
A(void) : SomeInt(0) { }
virtual ~A(void) { }
const wchar_t* Id(void) const { return L"A"; }
virtual const wchar_t* VirtId(void) const { return L"A"; }
int GetSomeInt(void) const { return SomeInt; }
int SomeInt;
};
class B1 : virtual public A
{
public:
B1(void) :
A(),
m_fValue(10.0f)
{
// Because SomeInt isn't a member of B, we
// cannot initialize it in the initializer list
// before the open brace where we initialize the
// A base class and the m_fValue member data.
SomeInt = 10;
}
virtual ~B1(void) { }
const wchar_t* Id(void) const { return L"B1"; }
virtual const wchar_t* VirtId(void) const override
{
return L"B1";
}
const wchar_t* Conflict(void) const { return L"B1::Conflict()"; }
private:
float m_fValue;
};
class B2 : virtual public A
{
public:
B2(void) : A() { }
virtual ~B2(void) { }
const wchar_t* Id(void) const { return L"B2"; }
virtual const wchar_t* VirtId(void) const override
{
return L"B2";
}
const wchar_t* Conflict(void) const { return L"B2::Conflict()"; }
};
class B3 : public A
{
public:
B3(void) : A() { }
virtual ~B3(void) { }
const wchar_t* Id(void) const { return L"B3"; }
virtual const wchar_t* VirtId(void) const override
{
return L"B3";
}
const wchar_t* Conflict(void) const { return L"B3::Conflict()"; }
};
class VirtualClass : virtual public B1, virtual public B2
{
public:
VirtualClass(void) :
B1(),
B2(),
m_id(L"VirtualClass")
{ }
virtual ~VirtualClass(void) { }
const wchar_t* Id(void) const { return m_id.c_str(); }
virtual const wchar_t* VirtId(void) const override
{
return m_id.c_str();
}
private:
wstring m_id;
};
// Note: If you were trying to inherit from A before inheriting from B1
// and B3, there would be a Visual C++ compiler error. If you
// tried to inherit from it after B1 and B3, there would still be a
// compiler warning. If you both indirectly and directly inherit
// from a class, it is impossible to get at the direct inheritance
// version of it.
class NonVirtualClass : public B1, public B3
{
public:
NonVirtualClass(void) :
B1(),
B3(),
m_id(L"NonVirtualClass")
{ }
virtual ~NonVirtualClass(void) { }
const wchar_t* Id(void) const { return m_id.c_str(); }
virtual const wchar_t* VirtId(void) const override
{
return m_id.c_str();
}
//// If we decided we wanted to use B1::Conflict, we could use
//// a using declaration. In this case, we would be saying that
//// calling NonVirtualClass::Conflict means call B1::Conflict
//using B1::Conflict;
//// We can also use it to resolve ambiguity between member
//// data. In this case, we would be saying that
//// NonVirtualClass::SomeInt means B3::SomeInt, so
//// the nvC.SomeInt statement in
//// DemonstrateNonVirtualInheritance would be legal, even
//// though IntelliSense says otherwise.
//using B3::SomeInt;
private:
wstring m_id;
};
void DemonstrateNonVirtualInheritance(void)
{
NonVirtualClass nvC = NonVirtualClass();
//// SomeInt is ambiguous since there are two copies of A, one
//// indirectly from B1 and the other indirectly from B3.
//nvC.SomeInt = 20;
// But you can access the two copies of SomeInt by specifying which
// base class' SomeInt you want. Note that if NonVirtualClass also
// directly inherited from A, then this too would be impossible.
nvC.B1::SomeInt = 20;
nvC.B3::SomeInt = 20;
//// It is impossible to create a reference to A due to ambiguity.
//A& nvCA = nvC;
// We can create references to B1 and B3 though.
B1& nvCB1 = nvC;
B3& nvCB3 = nvC;
// If we want a reference to some particular A, we can now get one.
A& nvCAfromB1 = nvCB1;
A& nvCAfromB3 = nvCB3;
// To demonstrate that there are two copies of A's data.
wcout <<
L"B1::SomeInt = " << nvCB1.SomeInt << endl <<
L"B3::SomeInt = " << nvCB3.SomeInt << endl <<
endl;
++nvCB1.SomeInt;
nvCB3.SomeInt += 20;
wcout <<
L"B1::SomeInt = " << nvCB1.SomeInt << endl <<
L"B3::SomeInt = " << nvCB3.SomeInt << endl <<
endl;
// Let's see a final demo of the result. Note that the Conflict
// member function is also ambiguous because both B1 and B3 have
// a member function named Conflict with the same signature.
wcout <<
typeid(nvC).name() << endl <<
nvC.Id() << endl <<
nvC.VirtId() << endl <<
//// This is ambiguous between B1 and B3
//nvC.Conflict() << endl <<
// But we can solve that ambiguity.
nvC.B3::Conflict() << endl <<
nvC.B1::Conflict() << endl <<
//// GetSomeInt is ambiguous too.
//nvC.GetSomeInt() << endl <<
endl <<
typeid(nvCB3).name() << endl <<
nvCB3.Id() << endl <<
nvCB3.VirtId() << endl <<
nvCB3.Conflict() << endl <<
endl <<
typeid(nvCB1).name() << endl <<
nvCB1.Id() << endl <<
nvCB1.VirtId() << endl <<
nvCB1.GetSomeInt() << endl <<
nvCB1.Conflict() << endl <<
endl;
}
void DemonstrateVirtualInheritance(void)
{
VirtualClass vC = VirtualClass();
// This works since VirtualClass has virtual inheritance of B1,
// which has virtual inheritance of A, and VirtualClass has virtual
// inheritance of A, which means all inheritances of A are virtual
// and thus there is only one copy of A.
vC.SomeInt = 20;
// We can create a reference directly to A and also to B1 and B2.
A& vCA = vC;
B1& vCB1 = vC;
B2& vCB2 = vC;
// To demonstrate that there is just one copy of A's data.
wcout <<
L"B1::SomeInt = " << vCB1.SomeInt << endl <<
L"B3::SomeInt = " << vCB2.SomeInt << endl <<
endl;
++vCB1.SomeInt;
vCB2.SomeInt += 20;
wcout <<
L"B1::SomeInt = " << vCB1.SomeInt << endl <<
L"B3::SomeInt = " << vCB2.SomeInt << endl <<
endl;
// Let's see a final demo of the result. Note that the Conflict
// member function is still ambiguous because both B1 and B2 have
// a member function named Conflict with the same signature.
wcout <<
typeid(vC).name() << endl <<
vC.Id() << endl <<
vC.VirtId() << endl <<
vC.B2::Id() << endl <<
vC.B2::VirtId() << endl <<
vC.B1::Id() << endl <<
vC.B1::VirtId() << endl <<
vC.A::Id() << endl <<
vC.A::VirtId() << endl <<
// This is ambiguous between B1 and B2
//vC.Conflict() << endl <<
// But we can solve that ambiguity.
vC.B2::Conflict() << endl <<
vC.B1::Conflict() << endl <<
// There's no ambiguity here because of virtual inheritance.
vC.GetSomeInt() << endl <<
endl <<
typeid(vCB2).name() << endl <<
vCB2.Id() << endl <<
vCB2.VirtId() << endl <<
vCB2.Conflict() << endl <<
endl <<
typeid(vCB1).name() << endl <<
vCB1.Id() << endl <<
vCB1.VirtId() << endl <<
vCB1.GetSomeInt() << endl <<
vCB1.Conflict() << endl <<
endl <<
typeid(vCA).name() << endl <<
vCA.Id() << endl <<
vCA.VirtId() << endl <<
vCA.GetSomeInt() << endl <<
endl;
}
int _pmain(int /*argc*/, _pchar* /*argv*/[])
{
DemonstrateNonVirtualInheritance();
DemonstrateVirtualInheritance();
return 0;
}
Note: Many of the member functions in the previous sample are declared as const by including the const keyword after the parameter list in the declaration. This notation is part of the concept of const-correctness, which we will discuss elsewhere. The only thing that the const-member-function notation means is that the member function is not changing any member data of the class; you do not need to worry about side effects when calling it in a multi-threading scenario. The compiler enforces this notation so you can be sure a function you mark as const really is const.
The previous sample demonstrates the difference between virtual member functions and non-virtual member functions. The Id function in class A is non-virtual while the VirtId function is virtual. The result is that when creating a base class reference to NonVirtualClass and call Id, we receive the base class’ version of Id, whereas when we call VirtId, we receive NonVirtualClass’s version of VirtId.
The same is true for VirtualClass, of course. Though the sample is careful to always specify virtual and override for the overrides of VirtId (and you should be too), as long as A::VirtId is declared as being virtual, then all derived class methods with the same signature will be considered virtual overrides of VirtId.
The previous sample also demonstrates the diamond problem that multiple-inheritance can produce as well as how virtual inheritance solves it. The diamond problem moniker comes from the idea that if class Z derives from class X and class Y, which both derive from class W, a diagram of this inheritance relationship would look like a diamond. Without virtual inheritance, the inheritance relationship does not actually form a diamond; instead, it forms a two-pronged fork with each prong having its own W.
NonVirtualClass has non-virtual inheritance from B1, which has virtual inheritance from A, and from B3, which has non-virtual inheritance from A. This results in a diamond problem, with two copies of the A class’ member data becoming a part of NonVirtualClass’ member data. The DemonstrateNonVirtualInheritance function shows the problems that result from this and also shows the syntax used to resolve which A you want when you need to use one of A’s members.
VirtualClass has virtual inheritance from both B1, which has virtual inheritance from A, and from B2, which also has virtual inheritance from A. Since all the inheritance chains that go from VirtualClass to A are virtual, there is only one copy of A’s data; thus, the diamond problem is avoided. The DemonstrateVirtualInheritance function shows this.
Even with virtual inheritance, VirtualClass still has one ambiguity. B1::Conflict and B2::Conflict both have the same name and same parameters (none, in this case), so it is impossible to resolve which one you want without using the base-class-specifier syntax.
Naming is very important when dealing with multiple-inheritance if you wish to avoid ambiguity. There is, however, a way to resolve ambiguity. The two commented-out using declarations in NonVirtualClass demonstrate this resolution mechanism. If we decided we wanted to always resolve an ambiguity in a certain way, the using declaration lets us do that.
Note: The using declaration is useful for resolving ambiguity outside of a class too (within a namespace or a function, for instance). It is also useful if you wish to bring only certain types from a namespace into scope without bringing the entire namespace into scope with a using namespace directive. It is okay to use a using declaration within a header, provided it is inside a class, structure, union, or function definition, since using declarations are limited to the scope in which they exist. You should not use them outside of these since you would be bringing that type into scope within the global namespace or within whatever namespace you were in.
One thing I did not touch on in the sample is inheritance access specifiers other than public. If you wanted, you could write something like class B : protected class A { ... }. Then class A’s members would be accessible from within B’s methods, and accessible to any class derived from B, but not publicly accessible. You could also say class B : private class A { ... }. Then class A’s members would be accessible from within B’s methods, but not accessible to any classes derived from B, nor would they be publicly accessible.
I mention these in passing simply because they are rarely used. You might, nonetheless, come across them, and you may even find a use for them. If so, remember that a class that privately inherits from a base class still has full access to that base class; you are simply saying that no further-derived classes should have access to the base class’ member functions and variables.
More common, you will come across mistakes where you or someone else forgot to type public before a base class specifier, resulting in the default private inheritance. You’ll recognize this by the slew of error messages telling you that you can’t access private member functions or data of some base class, unless you are writing a library and don’t test the class. In that case, you will recognize the issue from the angry roars of your users. One more reason unit testing is a good idea.
Abstract Classes
An abstract class has at least one pure virtual member function. The following sample shows how to mimic a C# interface.
Sample: AbstractClassSample\IWriteData.h
#pragma once
class IWriteData
{
public:
IWriteData(void) { }
virtual ~IWriteData(void) { }
virtual void Write(const wchar_t* value) = 0;
virtual void Write(double value) = 0;
virtual void Write(int value) = 0;
virtual void WriteLine(void) = 0;
virtual void WriteLine(const wchar_t* value) = 0;
virtual void WriteLine(double value) = 0;
virtual void WriteLine(int value) = 0;
};
Sample: AbstractClassSample\ConsoleWriteData.h
#pragma once
#include "IWriteData.h"
class ConsoleWriteData :
public IWriteData
{
public:
ConsoleWriteData(void) { }
virtual ~ConsoleWriteData(void) { }
virtual void Write(const wchar_t* value);
virtual void Write(double value);
virtual void Write(int value);
virtual void WriteLine(void);
virtual void WriteLine(const wchar_t* value);
virtual void WriteLine(double value);
virtual void WriteLine(int value);
};
Sample: AbstractClassSample\ConsoleWriteData.cpp
#include <iostream>
#include <ostream>
#include "ConsoleWriteData.h"
using namespace std;
void ConsoleWriteData::Write(const wchar_t* value)
{
wcout << value;
}
void ConsoleWriteData::Write(double value)
{
wcout << value;
}
void ConsoleWriteData::Write(int value)
{
wcout << value;
}
void ConsoleWriteData::WriteLine(void)
{
wcout << endl;
}
void ConsoleWriteData::WriteLine(const wchar_t* value)
{
wcout << value << endl;
}
void ConsoleWriteData::WriteLine(double value)
{
wcout << value << endl;
}
void ConsoleWriteData::WriteLine(int value)
{
wcout << value << endl;
}
Sample: AbstractClassSample\AbstractClassSample.cpp
#include "IWriteData.h"
#include "ConsoleWriteData.h"
#include "../pchar.h"
int _pmain(int /*argc*/, _pchar* /*argv*/[])
{
//// The following line is illegal since IWriteData is abstract.
//IWriteData iwd = IWriteData();
//// The following line is also illegal. You cannot have an
//// instance of IWriteData.
//IWriteData iwd = ConsoleWriteData();
ConsoleWriteData cwd = ConsoleWriteData();
// You can create an IWriteData reference to an instance of a class
// that derives from IWriteData.
IWriteData& r_iwd = cwd;
// You can also create an IWriteData pointer to an instance of a
// class that derives from IWriteData.
IWriteData* p_iwd = &cwd;
cwd.WriteLine(10);
r_iwd.WriteLine(14.6);
p_iwd->WriteLine(L"Hello Abstract World!");
return 0;
}
The previous sample demonstrates how to implement an interface-style class in C++. The IWriteData class could be inherited by a class that writes data to a log file, to a network connection, or to any other output. By passing around a pointer or a reference to IWriteData, you could easily switch output mechanisms.
The syntax for an abstract member function, called a pure virtual function, is simply to add = 0 after the declaration, as in IWriteData class: void Write(int value) = 0;. You do not need to make a class purely abstract; you can implement member functions or include member data common to all instances of the class. If a class has even one pure virtual function, then it is considered an abstract class.
Visual C++ provides a Microsoft-specific way to define an interface. Here’s the equivalent of IWriteData using the Microsoft syntax:
Sample: AbstractClassSample\IWriteData.h
#pragma once
__interface IWriteData
{
virtual void Write(const wchar_t* value) = 0;
virtual void Write(double value) = 0;
virtual void Write(int value) = 0;
virtual void WriteLine(void) = 0;
virtual void WriteLine(const wchar_t* value) = 0;
virtual void WriteLine(double value) = 0;
virtual void WriteLine(int value) = 0;
};
Rather than define it as a class, you define it using the __interface keyword. You cannot define a constructor, a destructor, or any member functions other than pure virtual member functions. You also cannot inherit from anything other than other interfaces. You do not need to include the public access specifier since all member functions are public.
Precompiled Header Files
A precompiled header file is a special type of header file. Like a normal header file, you can stick both include statements and code definitions in it. What it does differently is help to speed up compile times.
The precompiled header will be compiled the first time you build your program. From then on, as long as you don't make changes to the precompiled header, or to anything included directly or indirectly in the precompiled header, the compiler can reuse the existing compiled version of the precompiled header. Your compile times will speed up because a lot of code (e.g., Windows.h and the C++ Standard Library headers) will not be recompiled for each build.
If you use a precompiled header file, you need to include it as the first include statement of every source code file. You should not, however, include it in any header files. If you forget to include it, or put other include statements above it, then the compiler will generate an error. This requirement is a consequence of how precompiled headers work.
Precompiled header files are not part of the C++ standard. Their implementation depends on the compiler vendor. If you have any questions about them, you should look at the compiler vendor’s documentation and make sure to specify which compiler you are using if you ask in an online forum.
Forward Declarations
As we’ve discussed, when you include a header file, the preprocessor simply takes all the code and inserts it right into the source code file that it is currently compiling. If that header file includes other header files, then all of those come in too.
Some header files are huge. Some include many other header files. Some are huge and include many other header files. The result is that a lot of code can wind up being compiled again and again simply because you include a header file in another header file.
One way to avoid the need to include header files within other header files is to use forward declarations. Consider the following code:
#pragma once
#include "SomeClassA.h"
#include "Flavor.h"
#include "Toppings.h"
class SomeClassB
{
public:
SomeClassB(void);
~SomeClassB(void);
int GetValueFromSomeClassA(
const SomeClassA* value
);
bool CompareTwoSomeClassAs(
const SomeClassA& first,
const SomeClassA& second
);
void ChooseFlavor(
Flavor flavor
);
void AddTopping(
Toppings topping
);
void RemoveTopping(
Toppings topping
);
private:
Toppings m_toppings;
Flavor m_flavor;
// Other member data and member functions...
};
We’ve included the SomeClassA.h, Flavor.h, and Toppings.h header files. SomeClassA is a class. Flavor is a scoped enum (specifically an enum class). Toppings is an un-scoped enum.
Look at our function definitions: We have a pointer to SomeClassA in GetValueFromSomeClassA. We have two references to SomeClassA in CompareTwoSomeClassAs. Then we have various uses of Flavor and Toppings.
In this case, we can eliminate all three of those include statements. Why? Because to compile this class definition, the compiler just needs to know the type of SomeClassA and the underlying data types of Flavor and Toppings. We can tell the compiler all of this with forward declarations.
#pragma once
class SomeClassA;
enum class Flavor;
enum Toppings : int;
class SomeClassB
{
public:
SomeClassB(void);
~SomeClassB(void);
int GetValueFromSomeClassA(
const SomeClassA* value
);
bool CompareTwoSomeClassAs(
const SomeClassA& first,
const SomeClassA& second
);
void ChooseFlavor(
Flavor flavor
);
void AddTopping(
Toppings topping
);
void RemoveTopping(
Toppings topping
);
private:
Toppings m_toppings;
Flavor m_flavor;
// Other member data and member functions...
};
The three lines after #pragma once tell the compiler everything it needs to know. It’s told that SomeClassA is a class, so it can establish its type for linkage purposes. It’s told that Flavor is an enum class, and thus it knows that it needs to reserve space for an int (the default underlying type of an enum class). Lastly, it’s told that Toppings is an enum with an underlying type of int, and thus it can reserve space for it as well.
If the definitions of those types in SomeClassA.h, Flavor.h, and Toppings.h did not match those forward declarations, then you would receive compiler errors. If you wanted a SomeClassA instance to be a member variable of SomeClassB, or if you wanted to pass one as an argument directly rather than as a pointer or a reference, then you would need to include SomeClassA. The compiler would then need to reserve space for SomeClassA and would need its full definition in order to determine its size in memory. Lastly, you still need to include those three header files in the SomeClassB.cpp source code file since you will be working with them within the SomeClassB member function definitions.
So what have we gained? Anytime you include SomeClassB.h in a source code file, that code file will not automatically contain all the code from SomeClassA.h, Flavor.h, and Toppings.h and compile with it. You might choose to include them if you need them, but you’ve eliminated their automatic inclusion and that of any header files they include.
Let’s say SomeClassA.h includes Windows.h because, in addition to giving you some value, it also works with a window in your application. You’ve suddenly reduced the lines of code (by thousands and thousands) that need to be compiled in any source code file that includes SomeClassB.h but does not include SomeClassA.h or Windows.h. If you include SomeClassB.h in several dozen files, you’re suddenly talking about tens to hundreds of thousands of lines of code.
Forward declarations can save a few milliseconds, or minutes, or hours (for large projects). They are not a magic solution to all problems of course, but they are a valuable tool that can save time when used properly.
Conclusion
That was a lot to take in. We've covered a lot of important aspects of the C++ language so make sure to revisit this article if you need to refresh your memory.
This lesson represents a chapter from C++ Succinctly, a free eBook from the team at Syncfusion.

Comments