Introduction
Recently I began building a community site on top of the Yii platform, which I'll write about soon as part of my Programming With Yii2 series. I wanted to make it easy to add links related to content on the site. While it's easy for people to paste URLs into forms, it becomes time-consuming to also provide title and source information.
In today's tutorial, I'm going to show you how to leverage PHP to scrape common metadata from web pages to make it easier for your users to participate and to build more interesting services.
Remember, I participate in the comment threads below, so tell me what you think! You can also reach me on Twitter @lookahead_io.
Getting Started
First, I built a form for people to add links by pasting the URL. I also created a Lookup button to use AJAX to request the web page be scraped for metadata information.
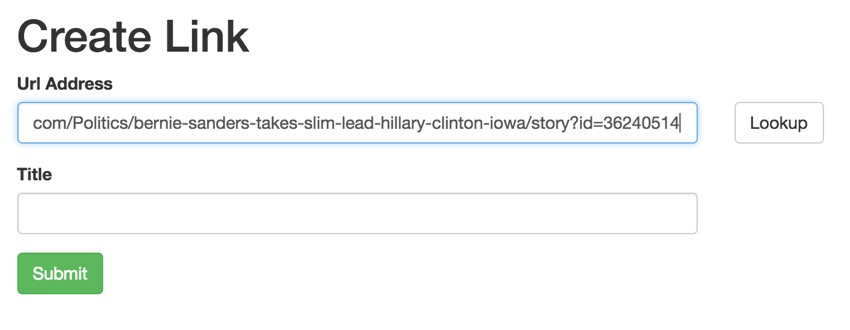
Pressing Lookup calls the Link::grab() function via ajax:
$(document).on("click", '[id=lookup]', function(event) {
$.ajax({
url: $('#url_prefix').val()+'/link/grab',
data: {url: $('#url').val()},
success: function(data) {
$('#title').val(data);
return true;
}
});
});
Scraping the Page
The Link::grab() code calls fetch_og(). This imitates a crawler to capture the page and get the metadata with DOMXPath:
public static function fetch_og($url)
{
$options = array('http' => array('user_agent' => 'facebookexternalhit/1.1'));
$context = stream_context_create($options);
$data = file_get_contents($url,false,$context);
$dom = new \DomDocument;
@$dom->loadHTML($data);
$xpath = new \DOMXPath($dom);
# query metatags with og prefix
$metas = $xpath->query('//*/meta[starts-with(@property, \'og:\')]');
$og = array();
foreach($metas as $meta){
# get property name without og: prefix
$property = str_replace('og:', '', $meta->getAttribute('property'));
$content = $meta->getAttribute('content');
$og[$property] = $content;
}
return $og;
}
For my scenario, I've replaced the og: tags above, but the code below looks for various types of tags:
$tags = Link::fetch_og($url);
if (isset($tags['title'])) {
$title = $tags['title'];
} else if (isset($tags['metaProperties']['og:title']['value'])) {
$title=$tags['metaProperties']['og:title']['value'];
} else {
$title = 'n/a';
}
return $title;
}
You can also grab other tags such as keywords, description, etc. The jQuery then adds the result to the form for the user to submit:

Going Further
I also have a table of sources which I'll develop more later. But basically, each time a new URL is added, we parse it for the base website domain and place it in a Source table:
$model->source_id = Source::add($model->url);
...
public static function add($url='',$name='') {
$source_url = parse_url($url);
$url = $source_url['host'];
$url = trim($url,' \\');
$s = Source::find()
->where(['url'=>$url])
->one();
if (is_null($s)) {
$s=new Source;
$s->url = $url;
$s->name = $name;
$s->status = Source::STATUS_ACTIVE;
$s->save();
} else {
if ($s->name=='') {
$s->name = $name;
$s->update();
}
}
return $s->id;
}
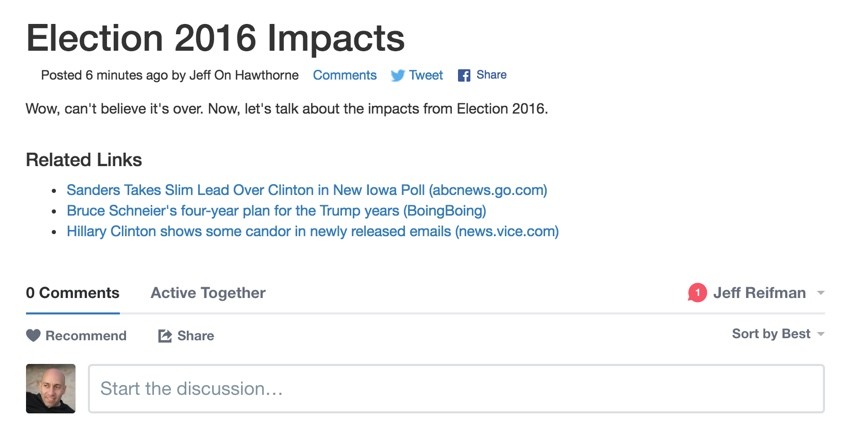
For now, I'm manually updating the names of sources so they'll look clean to the user, e.g. ABC News, BoingBoing, and Vice:

Hopefully, in an upcoming episode, I'll review how to use freely available APIs to look up the site's name. It's odd to me there's no common metatag for this; if only the Internet were perfect.
Paywall Sites
Some sites like The New York Times do not let you scrape the metadata because of their paywalls. But they do have an API. It's not easy to learn because of the confusing documentation, but their developers are quick to help on GitHub. I also hope to write about using the metadata lookup for New York Times titles in a future episode.
In Closing
I hope you found this scraping guide helpful and put it to use somewhere in your projects. If you'd like to see it in action, you can try out some of the web scraping on my site, Active Together.
Please do share any thoughts and feedback in the comments. You can also always reach me on Twitter @lookahead_io directly. And be sure to check out my instructor page and my other series, Building Your Startup With PHP and Programming With Yii2.

Comments