In this tutorial, you will learn how you can use Mechanize to click links, fill out forms, and upload files. You'll also learn how you can slice Mechanize page objects and how to automate a Google search and save its results.
Topics
- Single Page vs. Pagination
- Mechanize
- Agent
- Page
- Nokogiri Methods
- Links
- Click
- Forms
Single Page vs. Pagination
So far we have spent some time figuring out how we can scrape the screen of a single page using Nokogiri. This was a good basis to move one step forward and learn how to extract content from multiple pages.
After all, the problem we're trying to solve involves getting the content from more than 140 episodes—which is more content than can reasonably fit a single web page. We have to work with pagination and need to figure out how to follow content down the rabbit hole.
This is where Nokogiri stops and another useful gem called Mechanize comes into play.
Mechanize
Mechanize is another powerful tool that has lots of goodies to offer. It essentially enables you to automate interactions with websites you need to extract content from. In that sense it reminds me a bit of some functionality that you might know from testing with Capybara.
Don’t get me wrong, playing with Nokogiri on a single page is awesome in itself, but for more spicy data extraction jobs, we need a bit more horsepower. We can essentially crawl through as many pages as we need and interact with their elements—imitating and automating human behavior. Pretty powerful stuff!
This gem enables you to follow links, fill out form fields, and submit that data—even dealing with cookies is on the table. That means you can also imitate users' login into private sessions and get content from a site only you have access to.
You fill out the login with your credentials and tell Mechanize how to follow along. Since you can click links and submit forms, there is very little that you cannot do with this tool. It has a close relationship to Nokogiri and also depends on it. Aaron Patterson is again one of the authors of this lovely gem.
Instantiating a Mechanize Agent
Before we can start mechanizing things, we need to instantiate a Mechanize agent.
some_scraper.rb
require 'mechanize' agent = Mechanize.new
This agent will be used to fetch a page, similar to what we did with Nokogiri.
some_scraper.rb
require 'mechanize' agent = Mechanize.new podcast_url = "http://betweenscreens.fm/" page = agent.get(podcast_url)
What happens here is that the Mechanize agent got the podcast page and its cookies.
Extracting Page Content
We now have a page that is ready for extraction. Before we do so, I recommend that we take a look under the hood using the inspect method.
some_scraper.rb
require 'mechanize' agent = Mechanize.new podcast_url = "http://betweenscreens.fm/" page = agent.get(podcast_url) puts page.inspect
The output is quite substantive. Take a look and see for yourself what a Mechanize::Page object consists of. Here you can see all the attributes for that page.
To me, this is a really handy object to slice up the data you want to extract.
Output
#<Mechanize::Page
{url #http://betweenscreens.fm/>}
{meta_refresh}
{title "Between | Screens "}
{iframes
#<Mechanize::Page::Frame
nil
"https://w.soundcloud.com/player/?url=https%3A//api.soundcloud.com/tracks/290328784&color=ff0000&auto...>
#<Mechanize::Page::Frame
nil
"https://w.soundcloud.com/player/?url=https%3A//api.soundcloud.com/tracks/290126141&color=ff0000&auto...>
#<Mechanize::Page::Frame
nil
"https://w.soundcloud.com/player/?url=https%3A//api.soundcloud.com/tracks/289018386&color=ff0000&auto...>
#<Mechanize::Page::Frame
nil
"https://w.soundcloud.com/player/?url=https%3A//api.soundcloud.com/tracks/287425105&color=ff0000&auto...>
#<Mechanize::Page::Frame
nil
"https://w.soundcloud.com/player/?url=https%3A//api.soundcloud.com/tracks/287105342&color=ff0000&auto...>
#<Mechanize::Page::Frame
nil
"https://w.soundcloud.com/player/?url=https%3A//api.soundcloud.com/tracks/221003494&color=ff0000&auto...>
#<Mechanize::Page::Frame
nil
"">https://w.soundcloud.com/player/?url=https%3A//api.soundcloud.com/tracks/218101809&color=ff0000&auto...}
{frames}
{links
#<Mechanize::Page::Link "Logo cube" "/">
#https://github.com/vis-kid/betweenscreens">
#<Mechanize::Page::Link "about" "pages/about/">
#<Mechanize::Page::Link "design" "design/">
#<Mechanize::Page::Link "code" "code/">
#<Mechanize::Page::Link "Randy J. Hunt" "episodes/144/">
#<Mechanize::Page::Link "Jason Long" "episodes/143/">
#<Mechanize::Page::Link "David Heinemeier Hansson" "episodes/142/">
#<Mechanize::Page::Link "Zach Holman" "episodes/141/">
#<Mechanize::Page::Link "Joel Glovier" "episodes/140/">
#<Mechanize::Page::Link "João Ferreira" "episodes/139/">
#<Mechanize::Page::Link "Corwin Harrell" "episodes/138/">
#<Mechanize::Page::Link "Older Stuff »" "page/2/">
#<Mechanize::Page::Link "Exercise" "/tags/exercise/">
#<Mechanize::Page::Link "Company benefits" "/tags/company-benefits/">
#<Mechanize::Page::Link "Tmux" "/tags/tmux/">
#<Mechanize::Page::Link "FileTask" "/tags/filetask/">
#<Mechanize::Page::Link "Decision making" "/tags/decision-making/">
#<Mechanize::Page::Link "Favorite feature" "/tags/favorite-feature/">
#<Mechanize::Page::Link "Working out" "/tags/working-out/">
#<Mechanize::Page::Link "Scott Savarie" "/tags/scott-savarie/">
#<Mechanize::Page::Link "Titles" "/tags/titles/">
#<Mechanize::Page::Link "Erik Spiekermann" "/tags/erik-spiekermann/">
#<Mechanize::Page::Link "Newbie mistakes" "/tags/newbie-mistakes/">
#<Mechanize::Page::Link "Playbook" "/tags/playbook/">
#<Mechanize::Page::Link "Delegation" "/tags/delegation/">
#<Mechanize::Page::Link "Heat maps" "/tags/heat-maps/">
#<Mechanize::Page::Link "Europe" "/tags/europe/">
#<Mechanize::Page::Link "Sizing type" "/tags/sizing-type/">
#<Mechanize::Page::Link "Focus" "/tags/focus/">
#<Mechanize::Page::Link "Virtual assistants" "/tags/virtual-assistants/">
#<Mechanize::Page::Link "Writing" "/tags/writing/">
#<Mechanize::Page::Link "Hacking" "/tags/hacking/">
#<Mechanize::Page::Link "Joel Glovier" "/tags/joel-glovier/">
#<Mechanize::Page::Link "Corwin Harrell" "/tags/corwin-harrell/">
#<Mechanize::Page::Link "Mario C. Delgado" "/tags/mario-c-delgado/">
#<Mechanize::Page::Link "Tom Dale" "/tags/tom-dale/">
#<Mechanize::Page::Link "Obie Fernandez" "/tags/obie-fernandez/">
#<Mechanize::Page::Link "Chad Pytel" "/tags/chad-pytel/">
#<Mechanize::Page::Link "Zach Holman" "/tags/zach-holman/">
#<Mechanize::Page::Link "Max Luster" "/tags/max-luster/">
#<Mechanize::Page::Link "Kyle Fiedler" "/tags/kyle-fiedler/">
#<Mechanize::Page::Link "Roberto Machado" "/tags/roberto-machado/">}
{forms}>
If you want to take a look at the HTML page itself, you can tag on the body or content methods.
some_scraper.rb
... print page.body ...
Output
<!doctype html>
<html>
<head>
<meta charset="utf-8" />
<meta http-equiv='X-UA-Compatible' content='IE=edge;chrome=1' />
<meta content="IE=edge,chrome=1" http-equiv="X-UA-Compatible">
<meta name="viewport" content="initial-scale=1">
<title>Between | Screens </title>
<link rel="alternate" type="application/atom+xml" title="Atom Feed" href="/feed.xml" />
<link href="stylesheets/all-11b45acc.css" rel="stylesheet" />
<script src="javascripts/all-4c20da82.js"></script>
</head>
<body>
<header>
<div id="logo">
<a href="/"><img src="images/Between_Screens_Logo_Cube_Up-539d6997.svg" alt="Logo cube" /></a>
</div>
<nav class="navigation">
<ul class="nav-list">
fork">https://github.com/vis-kid/betweenscreens">fork!
<li><a href="pages/about/">about</a></li>
<li><a href="design/">design</a></li>
<li><a href="code/">code</a></li>
</ul>
</nav>
</header>
<div id="main" role="main">
<div class='posts'>
<ul>
<li>
<article class="index-article">
<span class='post-date'>Oct 27 | 2016</span><h2 class='post-title'><a href="episodes/144/">Randy J. Hunt</a></h2>
<h3 class='topic-list'>Organizing teams | Diversity | Desires | Pizza rule | Effective over clever | Novel solutions | Straightforwardness | Research | Coffeeshop test | Small changes | Reducing errors | Granular diffs</h3>
<div class='soundcloud-player-small'>
<iframe width="100%"
height="166"
scrolling="no"
frameborder="no"
src="https://w.soundcloud.com/player/?url=https%3A//api.soundcloud.com/tracks/290328784&color=ff0000&...>
</div>
</article>
</li>
<li>
<article class="index-article">
<span class='post-date'>Oct 25 | 2016</span><h2 class='post-title'><a href="episodes/143/">Jason Long</a></h2>
<h3 class='topic-list'>Open source | Empathy | Lower barriers | Learning tool | Design contributions | Git website | Branding | GitHub | Neovim | Tmux | Design love | Knowing audiences | Showing work | Dribbble | Progressions | Ideas</h3>
<div class='soundcloud-player-small'>
<iframe width="100%"
height="166"
scrolling="no"
frameborder="no"
src="https://w.soundcloud.com/player/?url=https%3A//api.soundcloud.com/tracks/290126141&color=ff0000&...>
</div>
</article>
</li>
<li>
<article class="index-article">
<span class='post-date'>Oct 18 | 2016</span><h2 class='post-title'><a href="episodes/142/">David Heinemeier Hansson</a></h2>
<h3 class='topic-list'>Rails community | Tone | Technical disagreements | Community policing | Ungratefulness | No assholes allowed | Basecamp | Open source persona | Aspirations | Guarding motivations | Dealing with audiences | Pressure | Honesty | Diverse opinions | Small talk</h3>
<div class='soundcloud-player-small'>
<iframe width="100%"
height="166"
scrolling="no"
frameborder="no"
src="https://w.soundcloud.com/player/?url=https%3A//api.soundcloud.com/tracks/289018386&color=ff0000&...>
</div>
</article>
</li>
<li>
<article class="index-article">
<span class='post-date'>Oct 12 | 2016</span><h2 class='post-title'><a href="episodes/141/">Zach Holman</a></h2>
<h3 class='topic-list'>Getting Fired | Taboo | Transparency | Different Perspectives | Timing | Growth Stages | Employment & Dating | Managers | At-will Employment | Tech Industry | Europe | Low hanging Fruits | Performance Improvement Plans | Meeting Goals | Surprise Firings | Firing Fast | Mistakes | Company Culture | Communication</h3>
<div class='soundcloud-player-small'>
<iframe width="100%"
height="166"
scrolling="no"
frameborder="no"
src="https://w.soundcloud.com/player/?url=https%3A//api.soundcloud.com/tracks/287425105&color=ff0000&...>
</div>
</article>
</li>
<li>
<article class="index-article">
<span class='post-date'>Oct 10 | 2016</span><h2 class='post-title'><a href="episodes/140/">Joel Glovier</a></h2>
<h3 class='topic-list'>Digital Product Design | Product Design @ GitHub | Loving Design | Order & Chaos | Drawing | Web Design | HospitalRun | Diversity | Startup Culture | Improving Lives | CURE International | Ember | Offline First | Hospital Information System | Designers & Open Source</h3>
<div class='soundcloud-player-small'>
<iframe width="100%"
height="166"
scrolling="no"
frameborder="no"
src="https://w.soundcloud.com/player/?url=https%3A//api.soundcloud.com/tracks/287105342&color=ff0000&...>
</div>
</article>
</li>
<li>
<article class="index-article">
<span class='post-date'>Aug 26 | 2015</span><h2 class='post-title'><a href="episodes/139/">João Ferreira</a></h2>
<h3 class='topic-list'>Masters @ Work | Subvisual | Deadlines | Design personality | Design problems | Team | Pushing envelopes | Delightful experiences | Perfecting details | Company values</h3>
<div class='soundcloud-player-small'>
<iframe width="100%"
height="166"
scrolling="no"
frameborder="no"
src="https://w.soundcloud.com/player/?url=https%3A//api.soundcloud.com/tracks/221003494&color=ff0000&...>
</div>
</article>
</li>
<li>
<article class="index-article">
<span class='post-date'>Aug 06 | 2015</span><h2 class='post-title'><a href="episodes/138/">Corwin Harrell</a></h2>
<h3 class='topic-list'>Q&A | 01 | University | Graphic design | Design setup | Sublime | Atom | thoughtbot | Working location | Collaboration & pairing | Vim advocates | Daily routine | Standups | Clients | Coffee walks | Investment Fridays |</h3>
<div class='soundcloud-player-small'>
<iframe width="100%"
height="166"
scrolling="no"
frameborder="no"
src="https://w.soundcloud.com/player/?url=https%3A//api.soundcloud.com/tracks/218101809&color=ff0000&...>
</div>
</article>
</li>
</ul>
</div>
<section>
<div class='pagination-link'><a href="page/2/">Older Stuff »</a></div>
</section>
</div>
<footer>
<div class='footer-tags'>
<h3>Random Tags</h3>
<ul class='random-tag-list'>
<li><a href="/tags/exercise/">Exercise</a></li>
<li><a href="/tags/company-benefits/">Company benefits</a></li>
<li><a href="/tags/tmux/">Tmux</a></li>
<li><a href="/tags/filetask/">FileTask</a></li>
<li><a href="/tags/decision-making/">Decision making</a></li>
<li><a href="/tags/favorite-feature/">Favorite feature</a></li>
<li><a href="/tags/working-out/">Working out</a></li>
<li><a href="/tags/scott-savarie/">Scott Savarie</a></li>
<li><a href="/tags/titles/">Titles</a></li>
<li><a href="/tags/erik-spiekermann/">Erik Spiekermann</a></li>
<li><a href="/tags/newbie-mistakes/">Newbie mistakes</a></li>
<li><a href="/tags/playbook/">Playbook</a></li>
<li><a href="/tags/delegation/">Delegation</a></li>
<li><a href="/tags/heat-maps/">Heat maps</a></li>
<li><a href="/tags/europe/">Europe</a></li>
<li><a href="/tags/sizing-type/">Sizing type</a></li>
<li><a href="/tags/focus/">Focus</a></li>
<li><a href="/tags/virtual-assistants/">Virtual assistants</a></li>
<li><a href="/tags/writing/">Writing</a></li>
<li><a href="/tags/hacking/">Hacking</a></li>
</ul>
</div>
<div class='recent-posts'>
<h3>Random Interviewees</h3>
<ul>
<li><a href="/tags/joel-glovier/">Joel Glovier</a></li>
<li><a href="/tags/corwin-harrell/">Corwin Harrell</a></li>
<li><a href="/tags/mario-c-delgado/">Mario C. Delgado</a></li>
<li><a href="/tags/tom-dale/">Tom Dale</a></li>
<li><a href="/tags/obie-fernandez/">Obie Fernandez</a></li>
<li><a href="/tags/chad-pytel/">Chad Pytel</a></li>
<li><a href="/tags/zach-holman/">Zach Holman</a></li>
<li><a href="/tags/max-luster/">Max Luster</a></li>
<li><a href="/tags/kyle-fiedler/">Kyle Fiedler</a></li>
<li><a href="/tags/roberto-machado/">Roberto Machado</a></li>
</ul>
</div>
</footer>
</body>
</html>
Since this podcast has only a small number of different elements on the page, here is the Mechanize::Page that gets returned from github.com. It has a bigger variety of content to take a look at. I think this is important to get a feel for.
Output github.com
#<Mechanize::Page
{url #https://github.com/>}
{meta_refresh}
{title "How people build software · GitHub"}
{iframes}
{frames}
{links
#<Mechanize::Page::Link "Skip to content" "#start-of-content">
#https://github.com/">
#<Mechanize::Page::Link "\n Personal\n" "/personal">
#<Mechanize::Page::Link "\n Open source\n" "/open-source">
#<Mechanize::Page::Link "\n Business\n" "/business">
#<Mechanize::Page::Link "\n Explore\n" "/explore">
#<Mechanize::Page::Link "Sign up" "/join?source=header-home">
#<Mechanize::Page::Link "Sign in" "/login">
#<Mechanize::Page::Link "Pricing" "/pricing">
#<Mechanize::Page::Link "Blog" "/blog">
#https://help.github.com">
#https://github.com/search">
#https://help.github.com/terms">
#https://help.github.com/privacy">
#<Mechanize::Page::Link "Sign up for GitHub" "/join?source=button-home">
#<Mechanize::Page::Link
"\n \n \n \n \n A whole new Universe\n \n Learn about the exciting features and announcements revealed at this year's GitHub Universe conference.\n \n \n "
"/universe-2016">
#<Mechanize::Page::Link "Individuals " "/personal">
#<Mechanize::Page::Link "Communities " "/open-source">
#<Mechanize::Page::Link "Businesses " "/business">
#<Mechanize::Page::Link "NASA" "//github.com/nasa">
#<Mechanize::Page::Link "Sign up for GitHub" "/join?source=button-home">
#https://github.com/contact">
#https://developer.github.com">
#https://training.github.com">
#https://shop.github.com">
#https://github.com/blog">
#https://github.com/about">
#https://github.com">
#https://github.com/site/terms">
#https://github.com/site/privacy">
#https://github.com/security">
#https://status.github.com/">
#https://help.github.com">
#<Mechanize::Page::Link "Reload" "">
#<Mechanize::Page::Link "Reload" "">}
{forms
#<Mechanize::Form
{name nil}
{method "GET"}
{action "/search"}
{fields
[hidden:0x3feb90f8297c type: hidden name: utf8 value: ✓]
[text:0x3feb90f827d8 type: text name: q value: ]}
{radiobuttons}
{checkboxes}
{file_uploads}
{buttons}>
#<Mechanize::Form
{name nil}
{method "POST"}
{action "/join"}
{fields
[hidden:0x3feb90f7be38 type: hidden name: utf8 value: ✓]
[hidden:0x3feb90f7bbb8 type: hidden name: authenticity_token value: vjRATKj7smXreq6Lt02r+MzW+ewWoi+fRzQXPedFAlOZgwzxQ0dZnChirhDfd7vyWZZZBO+ZFydLNedjIEDsrQ==]
[text:0x3feb90f7b9d8 type: text name: user[login] value: ]
[text:0x3feb90f7b7f8 type: text name: user[email] value: ]
[field:0x3feb90f7b654 type: password name: user[password] value: ]
[hidden:0x3feb90f7b474 type: hidden name: source value: form-home]}
{radiobuttons}
{checkboxes}
{file_uploads}
{buttons [button:0x3feb90f7a038 type: submit name: value: ]}>}>
Back to the podcast, you can also look at things like encodings, the HTTP response code, the URI, or the response headers.
some_scraper.rb
require 'mechanize' agent = Mechanize.new podcast_url = "http://betweenscreens.fm/" page = agent.get(podcast_url) puts 'Encodings' puts page.encodings puts 'Repsonse Headers' puts page.response puts 'HTTP response code' puts page.code puts 'URI' puts page.uri
Output
Encodings
EUC-JP
utf-8
utf-8
Repsonse Headers
{"server"=>"GitHub.com", "date"=>"Sat, 29 Oct 2016 17:56:00 GMT", "content-type"=>"text/html; charset=utf-8", "transfer-encoding"=>"chunked", "last-modified"=>"Fri, 28 Oct 2016 01:48:56 GMT", "access-control-allow-origin"=>"*", "expires"=>"Sat, 29 Oct 2016 18:06:00 GMT", "cache-control"=>"max-age=600", "content-encoding"=>"gzip", "x-github-request-id"=>"501C936D:C723:1631523C:5814E2B0"}
HTTP response code
200
URI
http://betweenscreens.fm/
There is lots more stuff if you want to dig deeper. I’ll leave it at that.
Nokogiri Methods
atsearch
Mechanize uses Nokogiri to scrape data from pages. You can apply what you learned about Nokogiri in the first article and use it on Mechanize pages as well. That means that you generally use Mechanize to navigate pages and Nokogiri methods for your scraping needs.
For example, if you want to search a single object, you can use at, while search returns all objects that will match a selector on a particular page. To rephrase that, these methods will work both on Nokogiri document objects and Mechanize page objects.
some_scraper.rb
require 'mechanize'
agent = Mechanize.new
podcast_url = "http://betweenscreens.fm/"
page = agent.get(podcast_url)
first_title = page.at('h2.post-title')
all_titles = page.search('h2.post-title')
all_titles.each do |title|
puts title
end
puts " * "*33
puts first_title
Output
<h2 class="post-title"><a href="episodes/144/">Randy J. Hunt</a></h2> <h2 class="post-title"><a href="episodes/143/">Jason Long</a></h2> <h2 class="post-title"><a href="episodes/142/">David Heinemeier Hansson</a></h2> <h2 class="post-title"><a href="episodes/141/">Zach Holman</a></h2> <h2 class="post-title"><a href="episodes/140/">Joel Glovier</a></h2> <h2 class="post-title"><a href="episodes/139/">João Ferreira</a></h2> <h2 class="post-title"><a href="episodes/138/">Corwin Harrell</a></h2> * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * <h2 class="post-title"><a href="episodes/144/">Randy J. Hunt</a></h2>
Links
linkslink_withlinks_with
We can also navigate the whole site to our liking. Probably the most important part of Mechanize is its ability to let you play with links. Otherwise you could pretty much stick with Nokogiri on its own. Let’s take a look what we get returned if we ask a page for its links.
some_scraper.rb
require 'mechanize'
agent = Mechanize.new
podcast_url = "http://betweenscreens.fm/"
page = agent.get(podcast_url)
puts "#{page.links}"
Output
[#<Mechanize::Page::Link "Logo cube" "/"> , #https://github.com/vis-kid/betweenscreens"> , #<Mechanize::Page::Link "about" "pages/about/"> , #<Mechanize::Page::Link "design" "design/"> , #<Mechanize::Page::Link "code" "code/"> , #<Mechanize::Page::Link "Randy J. Hunt" "episodes/144/"> , #<Mechanize::Page::Link "Jason Long" "episodes/143/"> , #<Mechanize::Page::Link "David Heinemeier Hansson" "episodes/142/"> , #<Mechanize::Page::Link "Zach Holman" "episodes/141/"> , #<Mechanize::Page::Link "Joel Glovier" "episodes/140/"> , #<Mechanize::Page::Link "João Ferreira" "episodes/139/"> , #<Mechanize::Page::Link "Corwin Harrell" "episodes/138/"> , #<Mechanize::Page::Link "Older Stuff »" "page/2/"> , #<Mechanize::Page::Link "Exercise" "/tags/exercise/"> , #<Mechanize::Page::Link "Company benefits" "/tags/company-benefits/"> , #<Mechanize::Page::Link "Tmux" "/tags/tmux/"> , #<Mechanize::Page::Link "FileTask" "/tags/filetask/"> , #<Mechanize::Page::Link "Decision making" "/tags/decision-making/"> , #<Mechanize::Page::Link "Favorite feature" "/tags/favorite-feature/"> , #<Mechanize::Page::Link "Working out" "/tags/working-out/"> , #<Mechanize::Page::Link "Scott Savarie" "/tags/scott-savarie/"> , #<Mechanize::Page::Link "Titles" "/tags/titles/"> , #<Mechanize::Page::Link "Erik Spiekermann" "/tags/erik-spiekermann/"> , #<Mechanize::Page::Link "Newbie mistakes" "/tags/newbie-mistakes/"> , #<Mechanize::Page::Link "Playbook" "/tags/playbook/"> , #<Mechanize::Page::Link "Delegation" "/tags/delegation/"> , #<Mechanize::Page::Link "Heat maps" "/tags/heat-maps/"> , #<Mechanize::Page::Link "Europe" "/tags/europe/"> , #<Mechanize::Page::Link "Sizing type" "/tags/sizing-type/"> , #<Mechanize::Page::Link "Focus" "/tags/focus/"> , #<Mechanize::Page::Link "Virtual assistants" "/tags/virtual-assistants/"> , #<Mechanize::Page::Link "Writing" "/tags/writing/"> , #<Mechanize::Page::Link "Hacking" "/tags/hacking/"> , #<Mechanize::Page::Link "Joel Glovier" "/tags/joel-glovier/"> , #<Mechanize::Page::Link "Corwin Harrell" "/tags/corwin-harrell/"> , #<Mechanize::Page::Link "Mario C. Delgado" "/tags/mario-c-delgado/"> , #<Mechanize::Page::Link "Tom Dale" "/tags/tom-dale/"> , #<Mechanize::Page::Link "Obie Fernandez" "/tags/obie-fernandez/"> , #<Mechanize::Page::Link "Chad Pytel" "/tags/chad-pytel/"> , #<Mechanize::Page::Link "Zach Holman" "/tags/zach-holman/"> , #<Mechanize::Page::Link "Max Luster" "/tags/max-luster/"> , #<Mechanize::Page::Link "Kyle Fiedler" "/tags/kyle-fiedler/"> , #<Mechanize::Page::Link "Roberto Machado" "/tags/roberto-machado/"> ]
Holy moly, let’s break this down. Since we haven’t told Mechanize to look elsewhere, we got an array of links from only that very first page. Mechanize goes through that page in descending order and returns you this list of links from top to bottom. I have created a little image with green pointers to the various links that you can see in the output.
By the way, this is already showing you the end result of the redesign for my podcast. I think this version is a bit better for demonstration purposes. You also get a glimpse of how the final result looks and why I needed to scrape my old Sinatra site.
Screenshot
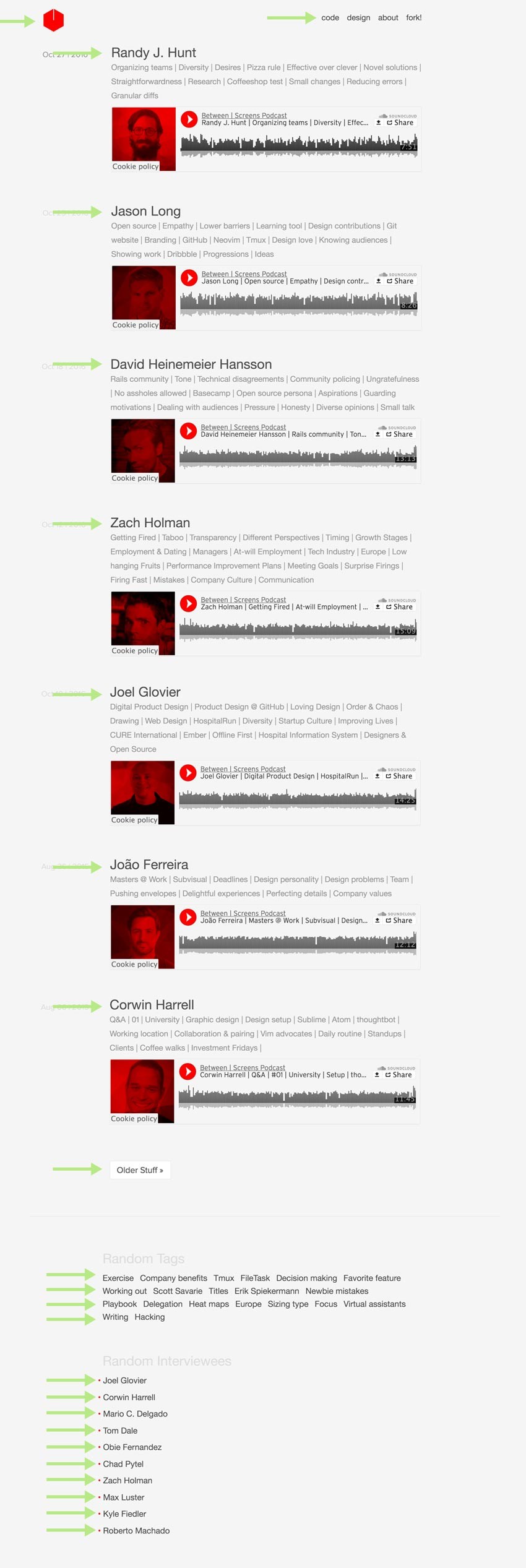
As always, we can also extract just the text from that.
some_scraper.rb
require 'mechanize' agent = Mechanize.new podcast_url = "http://betweenscreens.fm/" page = agent.get(podcast_url) page.links.each do |link| puts link.text end
Output
Logo cube fork! about design code Randy J. Hunt Jason Long David Heinemeier Hansson Zach Holman Joel Glovier João Ferreira Corwin Harrell Older Stuff » Exercise Company benefits Tmux FileTask Decision making Favorite feature Working out Scott Savarie Titles Erik Spiekermann Newbie mistakes Playbook Delegation Heat maps Europe Sizing type Focus Virtual assistants Writing Hacking Joel Glovier Corwin Harrell Mario C. Delgado Tom Dale Obie Fernandez Chad Pytel Zach Holman Max Luster Kyle Fiedler Roberto Machado
Getting all these links in bulk can be very useful or simply tedious. Luckily for us, we have a few tools in place to fine tune what we need.
some_scraper.rb
require 'mechanize'
agent = Mechanize.new
podcast_url = "http://betweenscreens.fm/"
page = agent.get(podcast_url)
focus_link = agent.page.links.find { |link| link.text == 'Focus' }
puts focus_link
Output
Focus
Boom! Now we are getting somewhere! We can zoom in on specific links like that. We can target links that match a certain criteria—like its text, for example—with a nicer API like links_with or link_with. Also, if we have multiple Focus links, we could zoom in on a particular number on the page using brackets [].
some_scraper.rb
require 'mechanize' agent = Mechanize.new podcast_url = "http://betweenscreens.fm/" page = agent.get(podcast_url) focus_link = agent.page.links_with(:text => 'Focus')[2] puts focus_link
If you are not after the link text but the link itself, you only need to specify a particular href to find that link. Mechanize won’t stand in your way. Instead of text, you feed the methods with href.
some_scraper.rb
page = agent.page.link_with(href: '/episodes/95/') page = agent.page.links_with(href: '/episodes/95/')
If you only want to find the first link with the desired text, you can also make use of this syntax. Very convenient and a bit more readable.
some_scraper.rb
focus_links = agent.page.link_with(:text => 'Focus')
What about following that fella and seeing what hides behind this Focus link? Let’s click it!
Click
some_scraper.rb
require 'mechanize'
agent = Mechanize.new
podcast_url = "http://betweenscreens.fm/"
page = agent.get(podcast_url)
focus_links = agent.page.links.find { |link| link.text == 'Focus' }.click.links
puts focus_links
This would get us another long list of links like before. See how easy it was to combine .click.links. Mechanize clicks the link for you and follows the page to the new destination. Since we also requested a list of links, we will get all the links that Mechanize can find on that new page.
Let’s say I have two text links of the same interviewee—one that links to tags and one to a recent episode—and I want to get the links from each of these pages.
some_scraper.rb
require 'mechanize' agent = Mechanize.new podcast_url = "http://betweenscreens.fm/" page = agent.get(podcast_url) links = agent.page.links_with(text: "Some interviewee") links.each do |link| puts link.click.links end
This would give you a list of links for both pages. You iterate over each link for the interviewee, and Mechanize follows the clicked link and collects the links it finds on the new page for you. Below you can find a few examples where you can compare combinations to get you started.
some_scraper.rb
agent.page.links.find { |l| l.text == 'Focus' }
agent.page.links.find { |l| l.text == 'Focus' }.click
agent.page.link_with(text: 'Focus')
agent.page.links_with(text: 'Focus')[0]
agent.page.links_with(text: 'Focus')[1].click
agent.page.links_with(text: 'Focus')[2].click.links
agent.page.link_with(href: '/some-href')
agent.page.link_with(href: '/some-href').click
agent.page.links_with(href: '/some-href')
agent.page.links_with(href: '/some-href').click
Forms
submitfield_withcheckbox_withradiobuttons_withfile_uploads
Let’s have a look at forms!
some_scraper.rb
require 'mechanize' agent = Mechanize.new google_url = "http://google.com/" page = agent.get(google_url) forms = page.forms puts forms.inspect
Output
[#<Mechanize::Form
# Attention!!
{name "f"}
# Attention!!
{method "GET"}
{action "/search"}
{fields
[hidden:0x3fea91d2eb08 type: hidden name: ie value: ISO-8859-1]
[hidden:0x3fea91d2e964 type: hidden name: hl value: es]
[hidden:0x3fea91d2e7e8 type: hidden name: source value: hp]
[hidden:0x3fea91d2e5f4 type: hidden name: biw value: ]
[hidden:0x3fea91d2e428 type: hidden name: bih value: ]
# Attention!!
[text:0x3fea91d2e248 type: name: q value: ]
# Attention!!
[hidden:0x3fea91d2bcb4 type: hidden name: gbv value: 1]}
{radiobuttons}
{checkboxes}
{file_uploads}
{buttons
[submit:0x3fea91d2e0f4 type: submit name: btnG value: Buscar con Google]
[submit:0x3fea91d2be80 type: submit name: btnI value: Voy a tener suerte]}>
]
Because we use the forms method, we get an array returned—even when we only have one form returned to us. Now that we know that the form has the name "f", we can use the singular version form to hone in on that one.
...
{name "f"}
...
some_scraper.rb
require 'mechanize'
agent = Mechanize.new
google_url = "http://google.com/"
page = agent.get(google_url)
search_form = page.form('f')
puts search_form.inspect
Using form('f'), we singled out the particular form we want to work with. As a result, we will not get an array returned.
Output
#<Mechanize::Form
# Attention!!
{name "f"}
# Attention!!
{method "GET"}
{action "/search"}
{fields
[hidden:0x3ffe9ce85ba4 type: hidden name: ie value: ISO-8859-1]
[hidden:0x3ffe9ce859d8 type: hidden name: hl value: es]
[hidden:0x3ffe9ce857bc type: hidden name: source value: hp]
[hidden:0x3ffe9ce85618 type: hidden name: biw value: ]
[hidden:0x3ffe9ce853e8 type: hidden name: bih value: ]
# Attention!!
[text:0x3ffe9ce851cc type: name: q value: ]
# Attention!!
[hidden:0x3ffe9ce84bdc type: hidden name: gbv value: 1]}
{radiobuttons}
{checkboxes}
{file_uploads}
{buttons
[submit:0x3ffe9ce85078 type: submit name: btnG value: Buscar con Google]
[submit:0x3ffe9ce84e48 type: submit name: btnI value: Voy a tener suerte]}>
We can also identify the name of the text input field (q).
... [text:0x3ffe9ce851cc type: name: q value: ] ...
We can target it by that name and set its value like Ruby attributes. All we need to do is provide it with a new value. You can see from the output example above that it is empty by default.
some_scraper.rb
require 'mechanize'
agent = Mechanize.new
google_url = "http://google.com/"
page = agent.get(google_url)
search_form = page.form('f')
search_form.q = 'New Google Search'
puts search_form.inspect
Output
#<Mechanize::Form
{name "f"}
{method "GET"}
{action "/search"}
{fields
[hidden:0x3fcb85b6a784 type: hidden name: ie value: ISO-8859-1]
[hidden:0x3fcb85b6a57c type: hidden name: hl value: es]
[hidden:0x3fcb85b6a3b0 type: hidden name: source value: hp]
[hidden:0x3fcb85b6a16c type: hidden name: biw value: ]
[hidden:0x3fcb85b67f20 type: hidden name: bih value: ]
# Attention!!
[text:0x3fcb85b67d18 type: name: q value: New Google Search]
# Attention!!
[hidden:0x3fcb85b67728 type: hidden name: gbv value: 1]}
{radiobuttons}
{checkboxes}
{file_uploads}
{buttons
[submit:0x3fcb85b67b9c type: submit name: btnG value: Buscar con Google]
[submit:0x3fcb85b67994 type: submit name: btnI value: Voy a tener suerte]}>
As you can observe above, the value for the text field has changed to New Google Search. Now we only need to submit the form and collect the results from the page that Google returns. It couldn’t be any easier. Let’s search for something else this time!
some_scraper.rb
require 'mechanize'
agent = Mechanize.new
google_url = "http://google.com/"
page = agent.get(google_url)
search_form = page.form('f')
search_form.q = 'GitHub TouchFart'
page = agent.submit(search_form)
pp page.search('h3.r').map(&:text)
Here I identified the search results header using a CSS selector h3.r, mapped its text, and pretty printed the results. Wasn’t that hard, was it? That is an easy example, sure, but think about the endless possibilities you have at your disposal with this!
Output
["GitHub - hungtruong/TouchFart: A fart app for the new Macbook ...", "TouchFart/TouchFart at master · hungtruong/TouchFart · GitHub", "Commits · hungtruong/TouchFart · GitHub", "Projects · hungtruong/TouchFart · GitHub", "Pull Requests · hungtruong/TouchFart · GitHub", "Issues · hungtruong/TouchFart · GitHub", "TouchFart/license.txt at master · hungtruong/TouchFart · GitHub", "Add autoplay attribute to <audio> tag and touchfart (er ... - GitHub", "Find file - File Finder · GitHub", "Fart app for the new Macbook Pro's Touch... #3860 on topic touchfart ..."]
Mechanize has different input fields available for you to play with. You can even upload files!
field_withcheckbox_withradiobuttons_withfile_uploads
You can also identify radio buttons and checkboxes by their name and check them with—you guessed it—check.
some_scraper.rb
form.radiobuttons_with(:name => 'gender')[3].check form.checkbox_with(:name => 'coder').check
Option tags offer users to select one item from a drop-down list. Again, we target them by name and select the option number we want.
some_scraper.rb
form.field_with(:name => 'countries').options[22].select
File uploads work similar to inputing text into forms by setting it like Ruby attributes. You identify the upload field and then specify the file path (file name) you want to transfer. It sounds more complicated than it is. Let’s have a look!
some_scraper.rb
form.file_uploads.first.file_name = "some-path/some-image.jpg"
Final Thoughts
See, no magic after all! You are now well equipped to have some fun on your own. There is certainly a bit more to learn about Nokogiri and Mechanize, but instead of spending too much time on unnecessary aspects, play around with it and look into some more documentation when you run into problems beyond the scope of a beginner article.
I hope you can see how beautifully simple this gem is and how much power it offers. As we all know from popular culture by now, this also bears responsibilities. Use it within legal frameworks and when you have no access to an API. You probably won’t have a frequent use for these tools, but boy do they come in handy when you have some real scraping needs ahead of you.
As promised, in the next article we will cover a real-world example where I will scrape data from my podcast site. I will extract it from an old Sinatra site and transfer it over to my new Middleman site that uses .markdown files for each episode. We will extract the dates, episodes numbers, interviewee names, headers, subheaders, and so on. See you there!

Comments