Git has become the most widely used system for version control and sharing code. If you want to help build open-source software, or if you want to work on a professional team, understanding Git is a must.
In a series of Git courses on Envato Tuts+, I explained some of the core Git concepts, all illustrated with helpful animations.
In this video, you'll learn about the three trees: the HEAD, the index, and the working directory. Watch as I explain the role of each and how they interact as you update and commit code.
Git Basics: The Three Trees
What Are the Three Trees?
To better understand how Git is operating, we can use the metaphor of the three trees. These trees are different collections of files.
For the workflow of adding and retrieving commits, Git uses three different versions of files:
- the working directory
- the index
- something called "HEAD" for creating and for retrieving commits

Each of these trees has a different job: one tree to write changes, one tree to stage them, and one to point to your last commit on a branch in your Git repo.
Different Versions of Files
Files whose contents can be changed are in your working directory. Files placed in your index are getting prepared to be packaged into a commit object. These commits are saved in your Git repository.
Files that have already been committed are compressed files. They are hashed through a SHA-1, a cryptographic hash function. Both file versions in the index and commit themselves are saved in the Git repo, which is simply a .git rectory at the root level of your wrap.
The working directory represents the actual files on your computer's file system that are available to your code editor to apply changes. The working directory is a version of a particular commit, a particular snapshot of a project that you checked out. It is the version of your Git history that HEAD is pointing at, at any given moment.
"Checked out" means that you have the decompressed versions of files that were pulled out of your Git repository, available for editing. The index represents what is being tracked. You could also say that it's a list of all the files that are relevant for your Git repository.

The index goes by a couple of names. When people talk about the staging area, staged files, cache, or directory cache, they are all talking about the index. You can see the index as the draft zone for your next commit, a temporary area to prepare the next commit.
HEAD
HEAD is the part of git that points to your branches, like the master branch by default. It's a reference, and it has a pretty simple but hugely important job. HEAD points to the currently checked out branch, and that in turn points back to the last commit from that branch. HEAD can move not only in time (when you check out previous commits), but it also moves when you create new branches or simply switch to other branches.
It's also the point in your Git history that you can place your next commit upon, the parent for your next commit. With every new commit, it replaces its reference to the branch currently checked out—by default, the master branch, of course.
So, in effect, HEAD is a reference that frequently changes and points to two things: the branch itself, and through that, the last commit on that branch.
Git's File Workflow
Let's have a closer look at the workflow of dealing with files in Git. It is essential to understand how all these pieces fit together. You'll have a much easier time to make sense of more advanced features and concepts in Git after that.
Here's an example:
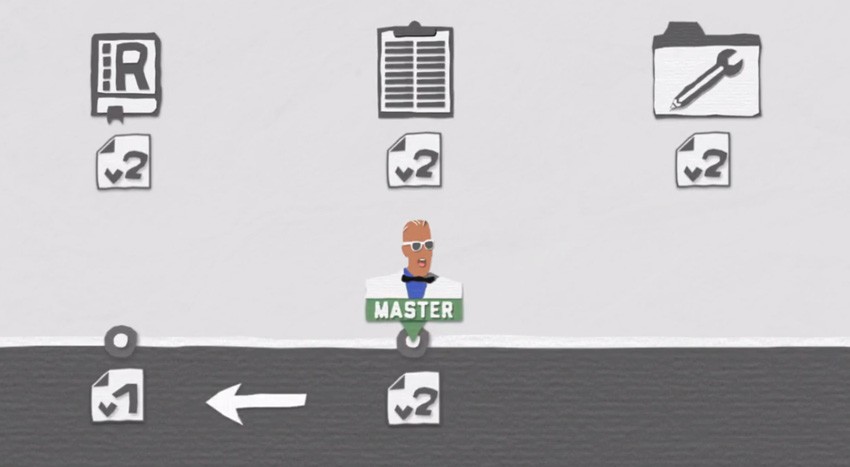
In this example, we have committed two versions of our file. And you can see that the versions in the repo, the index and the working directory are one and the same. Since these files are already tracked, Git will notice any differences when you change any of these tracked files in the working directory.
When you run the git status command, you will see a list of files that have been changed, colored in red. This indicates that you have differences between your working directory—represented by the code in your code editor—and your index, representing versions of files from a particular commit, most commonly the last commit.
You can now run the git add command to put these changes from the working directory into the index where you staged the files. git status will then show the files that are added to the index colored in green. This means that your changes are ready to be packaged into a new commit, which HEAD can point to and build upon.
A green list of files simply means that the versions of the staged files in the index are different from the versions of files that were already committed previously. When you run git commit, these staged files will be put into a new commit object. The git commit command will save the actual file names, the contents of each file, author information, metadata and such, in a new object.
This commit object, which now lives in a .git directory in your repo, will be the new reference that HEAD is pointing at. It points back to previous commits, being the tip of the iceberg in a way. After we've created our commit object, we are back at the beginning of the cycle.
The commit that HEAD points to in the repo is again matching the versions in the index and the working directory, which is ready for new changes to be staged and committed. End of story.
Watch More Git Courses
If you found this useful, why not check out some more Git courses?
You could watch our Introduction to Git and GitHub or try the other Coffee Break Courses in this series:

Comments