Introduction
Last week, I wrote an introduction to scraping web pages to collect metadata, mentioning that it's not possible to scrape the New York Times site. The Times paywall blocks your attempts to gather basic metadata. But there is a way around this using the New York Times API.
Recently I began building a community site on top of the Yii platform, which I will have published in a future tutorial. I wanted to make it easy to add links related to content on the site. While it's easy for people to paste URLs into forms, it becomes time-consuming to also provide title and source information.
So in today's tutorial, I'm going to expand the scraping code I wrote recently to leverage the New York Times API to gather headlines when Times links are added.
Remember, I participate in the comment threads below, so tell me what you think! You can also reach me on Twitter @lookahead_io.
Getting Started
Sign Up for an API Key

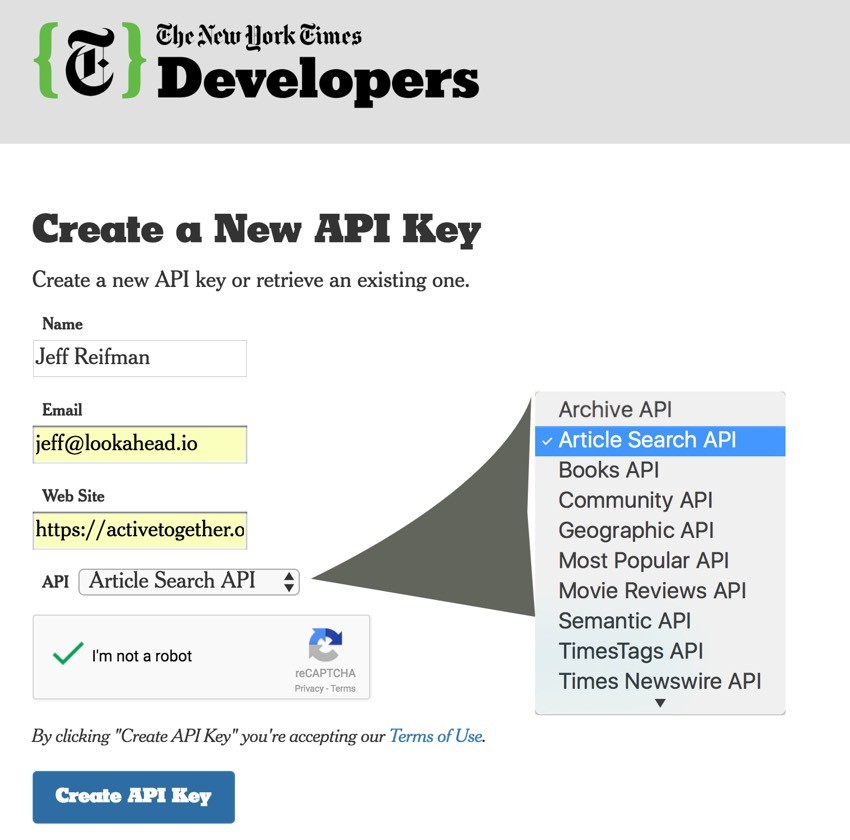
First, let's sign up to request an API Key:
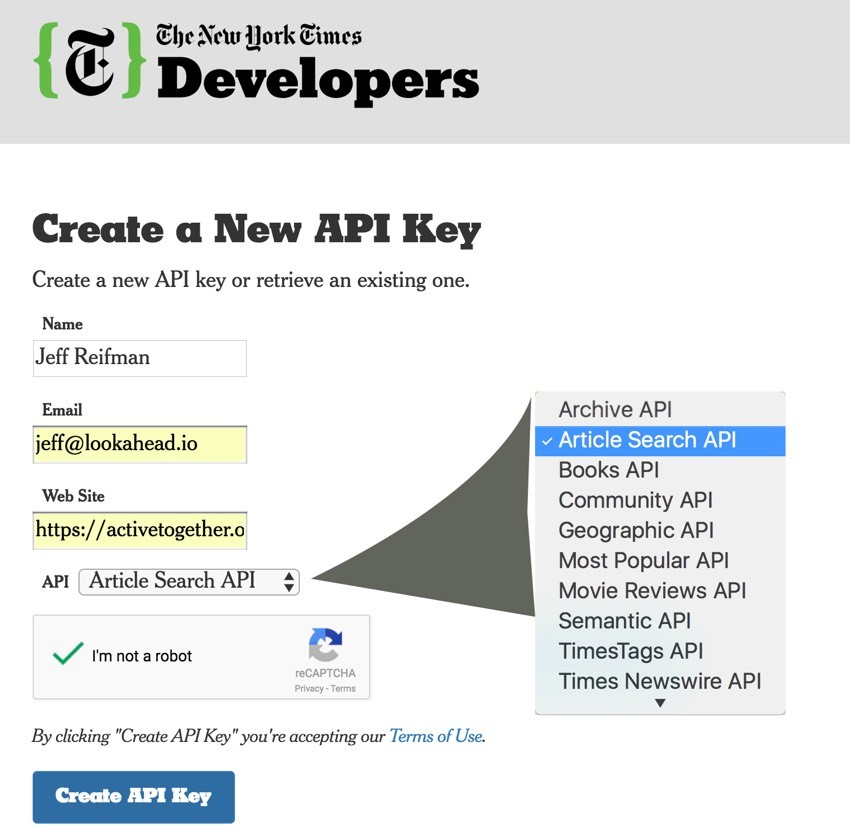
After you submit the form, you'll receive your key in an email:
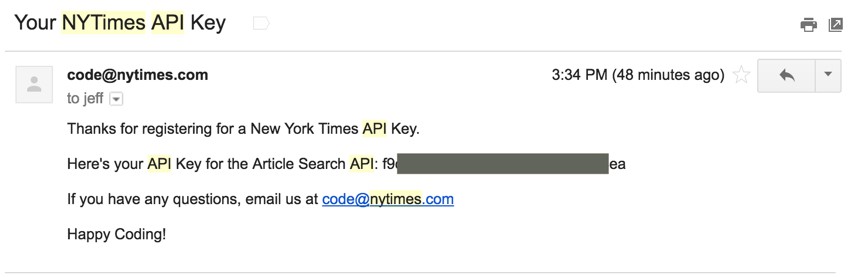
Exploring the New York Times API

The Times offers APIs in the following categories:
- Archive
- Article Search
- Books
- Community
- Geographic
- Most Popular
- Movie Reviews
- Semantic
- Times Newswire
- TimesTags
- Top Stories
It's a lot. And, from the Gallery page, you can click on any topic to see the individual API category documentation:
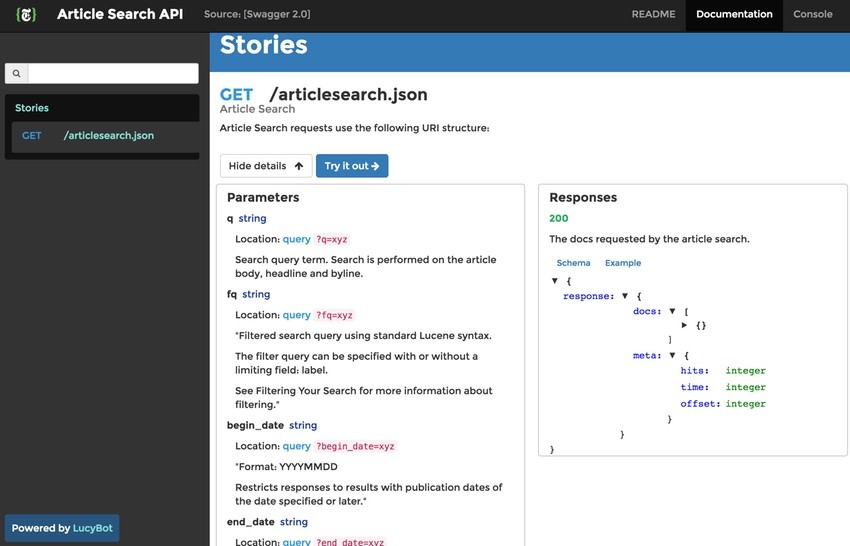
The Times uses LucyBot to power their API docs, and there is a helpful FAQ:

They even show you how to quickly get your API usage limits (you'll need to plug in your key):
curl --head
https://api.nytimes.com/svc/books/v3/lists/overview.json?api-key=<your-api-key>
2>/dev/null | grep -i "X-RateLimit"
X-RateLimit-Limit-day: 1000
X-RateLimit-Limit-second: 5
X-RateLimit-Remaining-day: 180
X-RateLimit-Remaining-second: 5
I initially struggled to make sense of the documentation—it's a parameter-based specification, not a programming guide. However, I posted some questions as issues to the New York Times API GitHub page, and they were quickly and helpfully answered.
Working With Article Search
For today's episode, I'm going to focus on using the NY Times Article Search. Basically, we'll extend the Create Link form from the last tutorial:
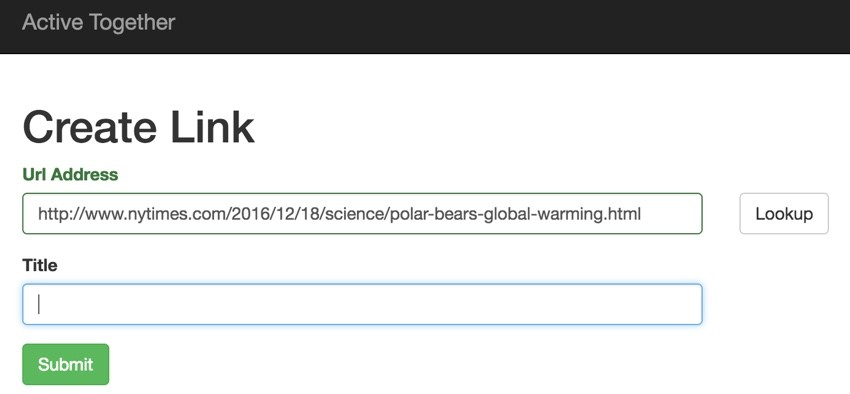
When the user clicks Lookup, we'll make an ajax request through to Link::grab($url). Here's the jQuery:
$(document).on("click", '[id=lookup]', function(event) {
$.ajax({
url: $('#url_prefix').val()+'/link/grab',
data: {url: $('#url').val()},
success: function(data) {
$('#title').val(data);
return true;
}
});
});
Here's the controller and model method:
// Controller call via AJAX Lookup request
public static function actionGrab($url) {
Yii::$app->response->format = Response::FORMAT_JSON;
return Link::grab($url);
}
...
// Link::grab() method
public static function grab($url) {
//clean up url for hostname
$source_url = parse_url($url);
$source_url = $source_url['host'];
$source_url=str_ireplace('www.','',$source_url);
$source_url = trim($source_url,' \\');
// use the NYT API when hostname == nytimes.com
if ($source_url=='nytimes.com') {
...
Next, let's use our API key to make an article search request:
$nytKey=Yii::$app->params['nytapi'];
$curl_dest = 'http://api.nytimes.com
/svc/search/v2/articlesearch.json?fl=headline&fq=web_url:%22'.
$url.'%22&api-key='.$nytKey;
$curl = curl_init();
curl_setopt($curl, CURLOPT_RETURNTRANSFER, true);
curl_setopt($curl, CURLOPT_URL,$curl_dest);
$result = json_decode(curl_exec($curl));
$title = $result->response->docs[0]->headline->main;
} else {
// not NYT, use the standard metatag scraper from last episode
...
}
}
return $title;
}
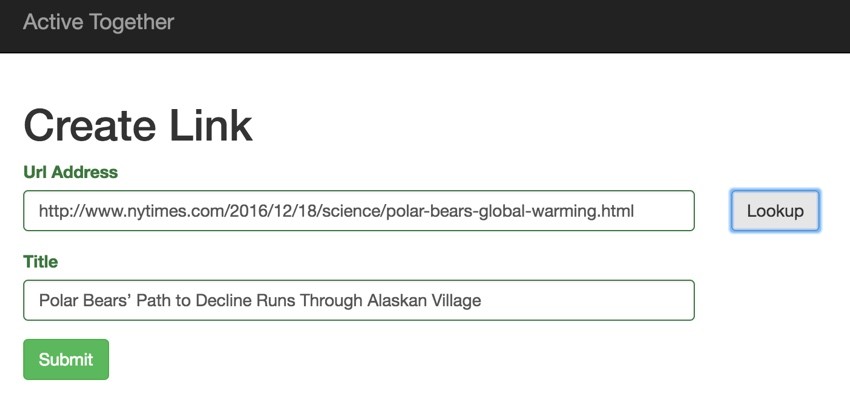
And it works quite easily—here's the resulting headline (by the way, climate change is killing Polar Bears and we should care):
If you want more details from your API request, just add additional arguments to the ?fl=headline request such as keywords and lead_paragraph:
Yii::$app->response->format = Response::FORMAT_JSON; $nytKey=Yii::$app->params['nytapi']; $curl_dest = 'http://api.nytimes.com/svc/search/v2/articlesearch.json?'. 'fl=headline,keywords,lead_paragraph&fq=web_url:%22'.$url.'%22&api-key='.$nytKey; $curl = curl_init(); curl_setopt($curl, CURLOPT_RETURNTRANSFER, true); curl_setopt($curl, CURLOPT_URL,$curl_dest); $result = json_decode(curl_exec($curl)); var_dump($result);
Here's the result:

Perhaps I'll write a PHP library to better parse the NYT API in coming episodes, but this code breaks out the keywords and the lead paragraph:
Yii::$app->response->format = Response::FORMAT_JSON;
$nytKey=Yii::$app->params['nytapi'];
$curl_dest = 'http://api.nytimes.com/svc/search/v2/articlesearch.json?'.
'fl=headline,keywords,lead_paragraph&fq=web_url:%22'.$url.'%22&api-key='.$nytKey;
$curl = curl_init();
curl_setopt($curl, CURLOPT_RETURNTRANSFER, true);
curl_setopt($curl, CURLOPT_URL,$curl_dest);
$result = json_decode(curl_exec($curl));
echo $result->response->docs[0]->headline->main.'<br />'.'<br />';
echo $result->response->docs[0]->lead_paragraph.'<br />'.'<br />';
foreach ($result->response->docs[0]->keywords as $k) {
echo $k->value.'<br/>';
}
Here's what it shows for this article:
Polar Bears’ Path to Decline Runs Through Alaskan Village The bears that come here are climate refugees, on land because the sea ice they rely on for hunting seals is receding. Polar Bears Greenhouse Gas Emissions Alaska Global Warming Endangered and Extinct Species International Union for Conservation of Nature National Snow and Ice Data Center Polar Bears International United States Geological Survey
Hopefully that starts to expand your imagination about how to use these APIs. It's pretty exciting what may now be possible.
In Closing
The New York Times API is very useful, and I'm glad to see them offering it to the developer community. It was also refreshing to get such quick API support via GitHub—I just didn't expect this. Keep in mind that it's intended for non-commercial projects. If you have some money-making idea, send them a note to see if they'll work with you. Publishers are eager for new sources of revenue.
I hope you found these web scraping episodes helpful and put them to use in your projects. If you'd like to see today's episode in action, you can try out some of the web scraping on my site, Active Together.
Please do share any thoughts and feedback in the comments. You can also always reach me on Twitter @lookahead_io directly. And be sure to check out my instructor page and other series, Building Your Startup With PHP and Programming With Yii2.

Comments