When we first start programming, we learn that a block of code executes from the top to the bottom. This is synchronous programming: each operation is completed before the next begins. This is great when you’re doing lots of things that take practically no time for a computer to complete, like adding numbers, manipulating a string, or assigning variables.
What happens when you want to do something that takes a relatively long time, like accessing a file on disk, sending a network request, or waiting for a timer to elapse? In synchronous programming, your script can do nothing else while it waits.
This might be fine for something simple or in a situation where you’ll have multiple instances of your script running, but for many server applications, it’s a nightmare.
Enter asynchronous programming. In an asynchronous script, your code continues to execute while waiting for something to happen, but can jump back when that something has happened.
Take, for example, a network request. If you make a network request to a slow server that takes a full three seconds to respond, your script can be actively doing other stuff while this slow server responds. In this case, three seconds might not seem like much to a human, but a server could respond to thousands of other requests while waiting. So, how do you handle asynchrony in Node.js?
The most basic way is through a callback. A callback is just a function that is called when an asynchronous operation is completed. By convention, Node.js callback functions have at least one argument, err. Callbacks may have more arguments (which usually represent the data returned to the callback), but the first one will be err. As you might have guessed, err holds an error object (if an error has been triggered—more on that later).
Let’s take a look at a very simple example. We’ll use Node.js’s built-in file system module (fs). In this script, we’ll read the contents of a text file. The last line of the file is a console.log that poses a question: if you run this script, do you think you’ll see the log before we see the contents of the text file?
var
fs = require('fs');
fs.readFile(
'a-text-file.txt', //the filename of a text file that says "Hello!"
'utf8', //the encoding of the file, in this case, utf-8
function(err,text) { //the callback
console.log('Error:',err); //Errors, if any
console.log('Text:',text); //the contents of the file
}
);
//Will this be before or after the Error / Text?
console.log('Does this get logged before or after the contents of the text file?');
Since this is asynchronous, we’ll actually see the last console.log before the contents of the text file. If you have a file named a-text-file.txt in the same directory in which you are executing your node script, you’ll see that err is null, and the value of text is populated with the contents of the text file.
If you don’t have a file named a-text-file.txt, err will return an Error object, and the value of text will be undefined. This leads to an important aspect of callbacks: you must always handle your errors. To handle errors, you need to check a value in the err variable; if a value is present, then an error occurred. By convention, err arguments usually don’t return false, so you can check only for truthiness.
var
fs = require('fs');
fs.readFile(
'a-text-file.txt', //the filename of a text file that says "Hello!"
'utf8', //the encoding of the file, in this case, utf-8
function(err,text) { //the callback
if (err) {
console.error(err); //display an error to the console
} else {
console.log('Text:',text); //no error, so display the contents of the file
}
}
);
Now, let’s say you want to display the contents of two files in a particular order. You’ll end up with something like this:
var
fs = require('fs');
fs.readFile(
'a-text-file.txt', //the filename of a text file that says "Hello!"
'utf8', //the encoding of the file, in this case, utf-8
function(err,text) { //the callback
if (err) {
console.error(err); //display an error to the console
} else {
console.log('First text file:',text); //no error, so display the contents of the file
fs.readFile(
'another-text-file.txt', //the filename of a text file that says "Hello!"
'utf8', //the encoding of the file, in this case, utf-8
function(err,text) { //the callback
if (err) {
console.error(err); //display an error to the console
} else {
console.log('Second text file:',text); //no error, so display the contents of the file
}
}
);
}
}
);
The code looks pretty nasty and has a number of problems:
-
You’re loading the files sequentially; it would be more efficient if you could load them both at the same time and return the values when both have loaded completely.
-
Syntactically it’s correct but difficult to read. Notice the number of nested functions and the increasing tabs. You could do some tricks to make it look a little better, but you may be sacrificing readability in other ways.
-
It’s not very general purpose. This works fine for two files, but what if you had nine files sometimes and other times 22 or just one? The way it is currently written is very rigid.
Don’t worry, we can solve all of these problems (and more) with async.js.
Callbacks With Async.js
First, let’s get started by installing the async.js module.
npm install async —-save
Async.js can be used to glue together arrays of functions in either series or parallel. Let’s rewrite our example:
var
async = require('async'), //async.js module
fs = require('fs');
async.series( //execute the functions in the first argument one after another
[ //The first argument is an array of functions
function(cb) { //`cb` is shorthand for "callback"
fs.readFile(
'a-text-file.txt',
'utf8',
cb
);
},
function(cb) {
fs.readFile(
'another-text-file.txt',
'utf8',
cb
);
}
],
function(err,values) { //The "done" callback that is ran after the functions in the array have completed
if (err) { //If any errors occurred when functions in the array executed, they will be sent as the err.
console.error(err);
} else { //If err is falsy then everything is good
console.log('First text file:',values[0]);
console.log('Second text file:',values[1]);
}
}
);
This works almost just like the previous example, sequentially loading each file, and differs only in that it reads each file and doesn’t display the result until it’s complete. The code is more concise and cleaner than the previous example (and we’ll make it even better later on). async.series takes an array of functions and executes them one after another.
Each function should only have a single argument, the callback (or cb in our code). cb should be executed with the same type of arguments as any other callback, so we can put it right into our fs.readFile arguments.
Finally, the results are sent to the final callback, the second argument in to async.series. The results are stored in an array with the values correlating with the order of the functions in the first argument of async.series.
With async.js, the error handling is simplified because if it encounters an error, it returns the error to the argument of the final callback and will not execute any further asynchronous functions.
All Together Now
A related function is async.parallel; it has the same arguments as async.series so you can change between the two without altering the rest of your syntax. This is a good point to cover parallel versus concurrent.
JavaScript is basically a single-threaded language, meaning it can only do one thing at a time. It is capable of doing some tasks in a separate thread (most I/O functions, for example), and this is where asynchronous programming comes into play with JS. Don’t confuse parallel with concurrency.
When you execute two things with async.parallel, you’re not making it open another thread to parse JavaScript or do two things at one time—you’re really controlling when it passes between functions in the first argument of async.parallel. So you don’t gain anything by just putting synchronous code in async.parallel.
This is best explained visually:
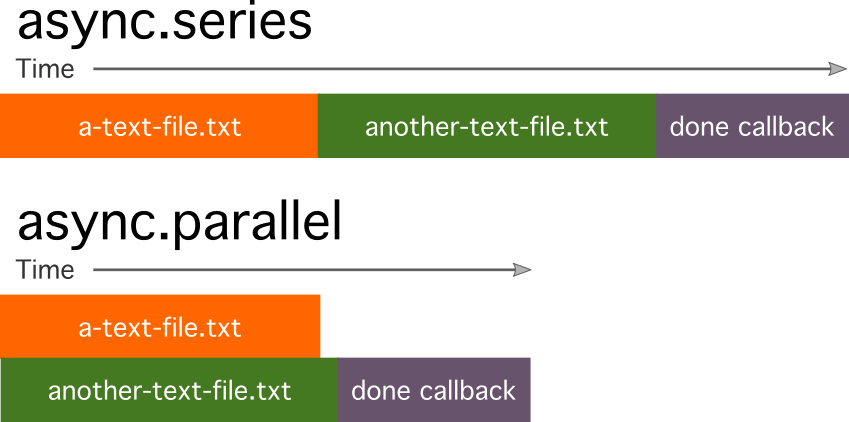
Here is our previous example written to be parallel—the only difference is that we use async.parallel rather than async.series.
var
async = require('async'), //async.js module
fs = require('fs');
async.parallel( //execute the functions in the first argument, but don't wait for the first function to finish to start the second
[ //The first argument is an array of functions
function(cb) { //`cb` is shorthand for "callback"
fs.readFile(
'a-text-file.txt',
'utf8',
cb
);
},
function(cb) {
fs.readFile(
'another-text-file.txt',
'utf8',
cb
);
}
],
function(err,values) { //The "done" callback that is ran after the functions in the array have completed
if (err) { //If any errors occurred when functions in the array executed, they will be sent as the err.
console.error(err);
} else { //If err is falsy then everything is good
console.log('First text file:',values[0]);
console.log('Second text file:',values[1]);
}
}
);
Over and Over
Our previous examples have executed a fixed number of operations, but what happens if you need a variable number of asynchronous operations? This gets messy quickly if you’re just relying on callbacks and regular language construct, relying on clumsy counters or condition checks that obscure the real meaning of your code. Let’s take a look at the rough equivalent of a for loop with async.js.
In this example, we’ll write ten files to the current directory with sequential filenames and some short contents. You can vary the number by changing the value of the first argument of async.times. In this example, the callback for fs.writeFile only creates an err argument, but the async.times function can also support a return value. Like async.series, it is passed to the done callback in the second argument as an array.
var
async = require('async'),
fs = require('fs');
async.times(
10, // number of times to run the function
function(runCount,callback) {
fs.writeFile(
'file-'+runCount+'.txt', //the new file name
'This is file number '+runCount, //the contents of the new file
callback
);
},
function(err) {
if (err) {
console.error(err);
} else {
console.log('Wrote files.');
}
}
);
It’s a good time to say that most async.js functions, by default, run in parallel rather than series. So, in the above example, it’ll start creating the files and report when all are completely created and written.
Those functions that run in parallel by default have a corollary series function indicated by the function ending with, you guessed it, 'Series'. So if you wanted to run this example in series rather than parallel, you would change async.times to async.timesSeries.
For our next example of looping, we’ll take a look at the async.until function. async.until executes an asynchronous function (in series) until a particular condition is met. This function takes three functions as arguments.
The first function is the test where you return either true (if you want to stop the loop) or false (if you want to continue the loop). The second argument is the asynchronous function, and the final is the done callback. Take a look at this example:
var
async = require('async'),
fs = require('fs'),
startTime = new Date().getTime(), //the unix timestamp in milliseconds
runCount = 0;
async.until(
function () {
//return true if 4 milliseconds have elapsed, otherwise false (and continue running the script)
return new Date().getTime() > (startTime + 5);
},
function(callback) {
runCount += 1;
fs.writeFile(
'timed-file-'+runCount+'.txt', //the new file name
'This is file number '+runCount, //the contents of the new file
callback
);
},
function(err) {
if (err) {
console.error(err);
} else {
console.log('Wrote files.');
}
}
);
This script will create new text files for five milliseconds. At the start of the script, we get the start time in the millisecond unix epoch, and then in the test function we get the current time and test to see if it is five milliseconds greater than the start time plus five. If you run this script multiple times, you might get different results.
On my machine, I was creating between 6 and 20 files in five milliseconds. Interestingly, if you try to add console.log into either the test function or the asynchronous function, you’ll get very different results because it is taking time to write to your console. It just goes to show you that in software, everything has a performance cost!
The for each loop is a handy structure—it allows you to do something for each item of an array. In async.js, this would be the async.each function. This function takes three arguments: the collection or array, the asynchronous function to perform for each item, and the done callback.
In the example below, we take an array of strings (in this case types of sighthound dog breeds) and create a file for each string. When all the files have been created, the done callback is executed. As you might expect, errors are handled via the err object in the done callback. async.each is run in parallel, but if you want to run it in series, you can follow the previously mentioned pattern and use async.eachSeries instead of async.each.
var
async = require('async'),
fs = require('fs');
async.each(
//an array of sighthound dog breeds
['greyhound','saluki','borzoi','galga','podenco','whippet','lurcher','italian-greyhound'],
function(dogBreed, callback) {
fs.writeFile(
dogBreed+'.txt', //the new file name
'file for dogs of the breed '+dogBreed, //the contents of the new file
callback
);
},
function(err) {
if (err) {
console.error(err);
} else {
console.log('Done writing files about dogs.');
}
}
);
A cousin of async.each is the async.map function; the difference is that you can pass the values back to your done callback. With the async.map function, you pass in an array or collection as the first argument, and then an asynchronous function will be run on each item in the array or collection. The last argument is the done callback.
The example below takes the array of dog breeds and uses each item to create a filename. The filename is then passed to fs.readFile, where it is read and the values are passed back by the callback function. You end up with an array of the file contents in the done callback arguments.
var
async = require('async'),
fs = require('fs');
async.map(
['greyhound','saluki','borzoi','galga','podenco','whippet','lurcher','italian-greyhound'],
function(dogBreed, callback) {
fs.readFile(
dogBreed+'.txt', //the new file name
'utf8',
callback
);
},
function(err, dogBreedFileContents) {
if (err) {
console.error(err);
} else {
console.log('dog breeds');
console.log(dogBreedFileContents);
}
}
);
async.filter is also very similar in syntax to async.each and async.map, but with filter you send a boolean value to the item callback rather than the value of the file. In the done callback you get a new array, with only the elements that you passed a true or truthy value for in the item callback.
var
async = require('async'),
fs = require('fs');
async.filter(
['greyhound','saluki','borzoi','galga','podenco','whippet','lurcher','italian-greyhound'],
function(dogBreed, callback) {
fs.readFile(
dogBreed+'.txt', //the new file name
'utf8',
function(err,fileContents) {
if (err) { callback(err); } else {
callback(
err, //this will be falsy since we checked it above
fileContents.match(/greyhound/gi) //use RegExp to check for the string 'greyhound' in the contents of the file
);
}
}
);
},
function(err, dogBreedFileContents) {
if (err) {
console.error(err);
} else {
console.log('greyhound breeds:');
console.log(dogBreedFileContents);
}
}
);
In this example, we’re doing a few more things than in the previous examples. Notice how we’re adding an additional function call and handling our own error. The if err and callback(err) pattern is very useful if you need to manipulate the results of an asynchronous function, but you still want to let async.js handle the errors.
Additionally, you’ll notice that we are using the err variable as the first argument to the callback function. At first blush, this doesn’t look quite right. But since we’ve already checked for the truthiness of err, we know that it is falsy and safe to pass to the callback.
Over the Edge of a Cliff
So far, we have explored a number of useful building blocks that have rough corollaries in synchronous programming. Let’s dive right into async.waterfall, which doesn’t have much of an equivalent in the synchronous world.
The concept with a waterfall is that the results of one asynchronous function flow into the arguments of another asynchronous function in series. It’s a very powerful concept, especially when trying to string together multiple asynchronous functions that rely on each other. With async.waterfall, the first argument is an array of functions, and the second argument is your done callback.
In your array of functions, the first function will always start with a single argument, the callback. Each subsequent function should match the non-err arguments of the previous function sans the err function and with the addition of the new callback.

In our next example, we’ll start combining some concepts using waterfall as a glue. In the array that is the first argument, we have three functions: the first loads the directory listing from the current directory, the second takes the directory listing and uses async.map to run fs.stat on each file, and the third function takes the directory listing from the first function result and gets the contents for each file (fs.readFile).
async.waterfall runs each function sequentially, so it will always run all the fs.stat functions before running any fs.readFile. In this first example, the second and third functions are not dependent on each other so they could be wrapped in an async.parallel to reduce the total execution time, but we’ll modify this structure again for the next example.
Note: Run this example in a small directory of text files, otherwise you’re going to get a lot of garbage for a long time in your terminal window.
var
async = require('async'),
fs = require('fs');
async.waterfall([
function(callback) {
fs.readdir('.',callback); //read the current directory, pass it along to the next function.
},
function(fileNames,callback) { //`fileNames` is the directory listing from the previous function
async.map(
fileNames, //The directory listing is just an array of filenames,
fs.stat, //so we can use async.map to run fs.stat for each filename
function(err,stats) {
if (err) { callback(err); } else {
callback(err,fileNames,stats); //pass along the error, the directory listing and the stat collection to the next item in the waterfall
}
}
);
},
function(fileNames,stats,callback) { //the directory listing, `fileNames` is joined by the collection of fs.stat objects in `stats`
async.map(
fileNames,
function(aFileName,readCallback) { //This time we're taking the filenames with map and passing them along to fs.readFile to get the contents
fs.readFile(aFileName,'utf8',readCallback);
},
function(err,contents) {
if (err) { callback(err); } else { //Now our callback will have three arguments, the original directory listing (`fileNames`), the fs.stats collection and an array of with the contents of each file
callback(err,fileNames,stats,contents);
}
}
);
}
],
function(err, fileNames,stats,contents) {
if (err) {
console.error(err);
} else {
console.log(fileNames);
console.log(stats);
console.log(contents);
}
}
);
Let’s say we want to get the results of only the files that have a size above 500 bytes. We could use the above code, but you’d be getting the size and contents of every file, whether you needed them or not. How could you just get the stat of the files and only the contents of the files that reach the size requirements?
First, we can pull all the anonymous functions out into named functions. It’s personal preference, but it makes the code a little cleaner and easier to understand (reusable to boot). As you might imagine, you’ll need to get the sizes, evaluate those sizes, and get only the contents of the files above the size requirement. This can be easily accomplished with something like Array.filter, but that is a synchronous function, and async.waterfall expects asynchronous-style functions. Async.js has a helper function that can wraps synchronous functions into asynchronous functions, the rather jazzily named async.asyncify.
We need to do three things, all of which we’ll wrap with async.asyncify. First, we’ll take the filename and stat arrays from the arrayFsStat function, and we’ll merge them using map. Then we’ll filter out any items that have a stat size less than 300. Finally, we’ll take the combined filename and stat object and use map again to just get the filename out.
After we’ve got the names of the files with a size less than 300, we’ll use async.map and fs.readFile to get the contents. There are many ways to crack this egg, but in our case it was broken up to show maximum flexibility and code reuse. This async.waterfall use illustrates how you can mix and match synchronous and asynchronous code.
var
async = require('async'),
fs = require('fs');
//Our anonymous refactored into named functions
function directoryListing(callback) {
fs.readdir('.',callback);
}
function arrayFsStat(fileNames,callback) {
async.map(
fileNames,
fs.stat,
function(err,stats) {
if (err) { callback(err); } else {
callback(err,fileNames,stats);
}
}
);
}
function arrayFsReadFile(fileNames,callback) {
async.map(
fileNames,
function(aFileName,readCallback) {
fs.readFile(aFileName,'utf8',readCallback);
},
function(err,contents) {
if (err) { callback(err); } else {
callback(err,contents);
}
}
);
}
//These functions are synchronous
function mergeFilenameAndStat(fileNames,stats) {
return stats.map(function(aStatObj,index) {
aStatObj.fileName = fileNames[index];
return aStatObj;
});
}
function above300(combinedFilenamesAndStats) {
return combinedFilenamesAndStats
.filter(function(aStatObj) {
return aStatObj.size >= 300;
});
}
function justFilenames(combinedFilenamesAndStats) {
return combinedFilenamesAndStats
.map(function(aCombinedFileNameAndStatObj) {
return aCombinedFileNameAndStatObj.fileName;
});
}
async.waterfall([
directoryListing,
arrayFsStat,
async.asyncify(mergeFilenameAndStat), //asyncify wraps synchronous functions in a err-first callback
async.asyncify(above300),
async.asyncify(justFilenames),
arrayFsReadFile
],
function(err,contents) {
if (err) {
console.error(err);
} else {
console.log(contents);
}
}
);
Taking this one step further, let's refine our function even further. Let’s say we want to write a function that works exactly as above, but with the flexibility to look in any path. A close cousin to async.waterfall is async.seq. While async.waterfall just executes a waterfall of functions, async.seq returns a function that performs a waterfall of other functions. In addition to creating a function, you can pass in values that will go into the first asynchronous function.
Converting to async.seq only takes a few modifications. First, we’ll modify directoryListing to accept an argument—this will be the path. Second, we’ll add a variable to hold our new function (directoryAbove300). Third, we’ll take the array argument from the async.waterfall and translate that into arguments for async.seq. Our done callback for the waterfall is now used as the done callback when we run directoryAbove300.
var
async = require('async'),
fs = require('fs'),
directoryAbove300;
function directoryListing(initialPath,callback) { //we can pass a variable into the first function used in async.seq - the resulting function can accept arguments and pass them this first function
fs.readdir(initialPath,callback);
}
function arrayFsStat(fileNames,callback) {
async.map(
fileNames,
fs.stat,
function(err,stats) {
if (err) { callback(err); } else {
callback(err,fileNames,stats);
}
}
);
}
function arrayFsReadFile(fileNames,callback) {
async.map(
fileNames,
function(aFileName,readCallback) {
fs.readFile(aFileName,'utf8',readCallback);
},
function(err,contents) {
if (err) { callback(err); } else {
callback(err,contents);
}
}
);
}
function mergeFilenameAndStat(fileNames,stats) {
return stats.map(function(aStatObj,index) {
aStatObj.fileName = fileNames[index];
return aStatObj;
});
}
function above300(combinedFilenamesAndStats) {
return combinedFilenamesAndStats
.filter(function(aStatObj) {
return aStatObj.size >= 300;
});
}
function justFilenames(combinedFilenamesAndStats) {
return combinedFilenamesAndStats
.map(function(aCombinedFileNameAndStatObj) {
return aCombinedFileNameAndStatObj.fileName;
})
}
//async.seq will produce a new function that you can use over and over
directoryAbove300 = async.seq(
directoryListing,
arrayFsStat,
async.asyncify(mergeFilenameAndStat),
async.asyncify(above300),
async.asyncify(justFilenames),
arrayFsReadFile
);
directoryAbove300(
'.',
function(err, fileNames,stats,contents) {
if (err) {
console.error(err);
} else {
console.log(fileNames);
}
}
);
A Note on Promises and Async Functions
You might be wondering why I haven't mentioned promises. I’ve got nothing against them—they’re quite handy and maybe a more elegant solution than callbacks—but they are a different way to look at asynchronous coding.
Built-in Node.js modules use err-first callbacks, and thousands of other modules use this pattern. In fact, that’s why this tutorial uses fs in the examples—something as fundamental as file system access in Node.js uses callbacks, so wrangling callback codes without promises is an essential part of Node.js programming.
It’s possible to use something like Bluebird to wrap err-first callbacks into Promise-based functions, but that only gets you so far—Async.js provides a host of metaphors that make asynchronous code readable and manageable.
Embrace Asynchrony
JavaScript has become one of the de facto languages of working on the web. It’s not without its learning curves, and there are plenty of frameworks and libraries to keep you busy, as well. If you’re looking for additional resources to study or to use in your work, check out what we have available in the Envato marketplace.
But learning asynchronous is something entirely different, and hopefully, this tutorial has shown you just how useful it can be.
Asynchrony is key to writing server-side JavaScript, yet if it's not crafted properly, your code can become an unmanageable beast of callbacks. By using a library like async.js that provides a number of metaphors, you might find that writing asynchronous code is a joy.

Comments