Being a purely functional language, Haskell limits you from many of the conventional methods of programming in an object-oriented language. But does limiting programming options truly offer us any benefits over other languages?
In this tutorial, we'll take a look at Haskell, and attempt to clarify what it is, and why it just might be worth using in your future projects.
Haskell at a Glance
Haskell is a very different kind of language.
Haskell is a very different kind of language than you may be used to, in the way that you arrange your code into "Pure" functions. A pure function is one that performs no outside tasks other than returning a computed value. These outside tasks are generally referred to as "Side-Effects.
This includes fetching outside data from the user, printing to the console, reading from a file, etc. In Haskell, you don't put any of these types of actions into your pure functions.
Now you may be wondering, "what good is a program, if it can't interact with the outside world?" Well, Haskell solves this with a special kind of function, called an IO function. Essentially, you separate all the data processing parts of your code into pure functions, and then put the parts which load data in and out into IO functions. The "main" function that is called when your program first runs is an IO function.
Let's review a quick comparison between a standard Java program, and it's Haskell equivalent.
Java Version:
import java.io.*;
class Test{
public static void main(String[] args)
{
System.out.println("What's Your Name: ");
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
String name = null;
try {
name = br.readLine();
}
catch(IOException e) {
System.out.println("There Was an Error");
}
System.out.println("Hello " + name);
}
}
Haskell Version:
welcomeMessage name = "Hello " ++ name
main = do
putStrLn "What's Your Name: "
name <- getLine
putStrLn $ welcomeMessage name
The first thing that you may notice when looking at a Haskell program is that there are no brackets. In Haskell , you only apply brackets when attempting to group things together. The first line at the top of the program - that starts with welcomeMessage - is actually a function; it accepts a string and returns the welcome message. The only other thing that may appear somewhat odd here is the dollar sign on the last line.
putStrLn $ welcomeMessage name
This dollar sign simply tells Haskell to first perform what's on the right side of the dollar sign, and then move on to the left. This is needed because, in Haskell, you could pass a function as a parameter to another function; so Haskell doesn't know if you are trying to pass the welcomeMessage function to putStrLn, or process it first.
Besides the fact that the Haskell program is considerably shorter than the Java implementation, the main difference is that we've separated the data processing into a pure function, whereas, in the Java version, we only printed it out. This is your job in Haskell in a nutshell: separating your code into its components. Why, you ask? Well. there are a couple of reasons; let's review some of them.
1. Safer Code
There is no way for this code to break.
If you've ever had programs crash on you in the past, then you know that the problem is always related to one of these unsafe operations, such as an error when reading a file, a user entered the wrong kind of data, etc. By limiting your functions to only processing data, your are guaranteed that they won't crash. The most natural comparison that most people are familiar with is a Math function.
In Math, a function computes a result; that's all. For example, if I were to write a Math function, like f(x) = 2x + 4, then, if I pass in x = 2, I will get 8. If I instead pass in x = 3, I will get 10 as a result. There is no way for this code to break. Additionally, since everything is split up into small functions, unit-testing becomes trivial; you can test each individual part of your program and move on knowing that it's 100% safe.
2. Increased Code Modularity
Another benefit to separating your code into multiple functions is code reusability. Imagine if all the standard functions, like min and max, also printed the value to the screen. Then, these functions would only be relevant in very unique circumstances, and, in most cases, you would have to write your own functions that only return a value without printing it. The same applies to your custom code. If you have a program that converts a measurement from cm to inches, you could put the actual conversion process into a pure function and then reuse it everywhere. However, if you hardcode it into your program, you will have to retype it every time. Now this seems fairly obvious in theory, but, if you remember the Java comparison from above, there are some things that we are used to just hardcoding in.
Additionally, Haskell offers two ways of combining functions: the dot operator, and higher order functions.
The dot operator allows you to chain functions together so that the output of one function goes into the input of the next.
Here is a quick example to demonstrate this idea:
cmToInches cm = cm * 0.3937
formatInchesStr i = show i ++ " inches"
main = do
putStrLn "Enter length in cm:"
inp <- getLine
let c = (read inp :: Float)
(putStrLn . formatInchesStr . cmToInches) c
This is similar to the last Haskell example, but, here, I've combined the output of cmToInches to the input of formatInchesStr, and have tied that output to putStrLn. Higher order functions are functions that accept other functions as an input, or functions that output a function as its output. A helpful example of this is Haskell's built-in map function. map takes in a function that was meant for a single value, and performs this function on an array of objects. Higher order functions allow you to abstract sections of code that multiple functions have in common, and then simply supply a function as a parameter to change the overall effect.
3. Better Optimisation
In Haskell, there is no support for changing state or mutable data.
In Haskell, there is no support for changing state or mutable data, so if you try to change a variable after it has been set, you will receive an error at compile time. This may not sound appealing at first, but it makes your program "referentially transparent". What this means is that your functions will always return the same values, provided the same inputs. This allows Haskell to simplify your function or replace it entirely with a cached value, and your program will continue to run normally, as expected. Again, a good analogy to this is Math functions - as all Math functions are referentially transparent. If you had a function, like sin(90), you could replace that with the number 1, because they have the same value, saving you time calculating this each time. Another benefit you get with this sort of code is that, if you have functions that don't rely on each other, you can run them in parallel - again boosting the overall performance of your application.
4. Higher Productivity in Workflow
Personally, I've found that this leads to a considerably more efficient workflow.
By making your functions individual components that don't rely on anything else, you are able to plan and execute your project in a much more focused manner. Conventionally, you would make a very generic to-do list that encompasses many things, such as "Build Object Parser" or something like that, which doesn't really allow you to know what's involved or how long it will take. You have a basic idea, but, many times, things tend to "come up."
In Haskell, most functions are fairly short - a couple of lines, max - and are quite focused. Most of them only execute a single specific task. But then, you have other functions, which are a combination of these lower-level functions. So your to-do list ends up being comprised of very specific functions, where you know exactly what each one does ahead of time. Personally, I've found that this leads to a considerably more efficient workflow.
Now this workflow is not exclusive to Haskell; you can easily do this in any language. The only difference is that this is the preferred way in Haskell, as apposed to other languages, where you are more likely to combine multiple tasks together.
This is why I recommended that you learn Haskell, even if you don't plan on using it every day. It forces you to get into this habit.
Now that I've given you a quick overview of some of the benefits to using Haskell, let's take a look at a real world example. Because this is a net-related site, I thought that a relevant demo would be to make a Haskell program that can backup your MySQL databases.
Let's start with some planning.
Building a Haskell Program
Planning
I mentioned earlier that, in Haskell, you don't really plan out your program in an overview type style. Instead, you organize the individual functions, while, at the same time, remembering to separate the code into pure and IO functions. The first thing this program has to do is connect to a database and get the list of tables. These are both IO functions, because they fetch data from an outside database.
Next, we have to write a function that will cycle through the list of tables and return all the entries - this is also an IO function. Once that's finished, we have a few pure functions to get the data ready for writing, and, last but not least, we have to write all the entries to backup files along with the date and a query to remove old entries. Here is a model of our program:
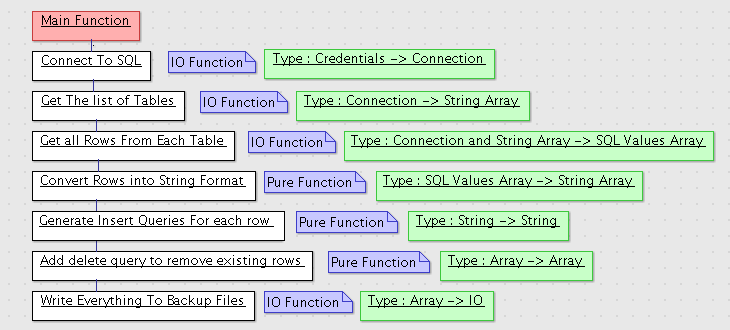
This is the main flow of the program, but, like I said, there will also be a few helper functions to do things like getting the date and such. Now that we have everything mapped out, we can begin building the program.
Building
I will be using the HDBC MySQL library in this program, which you can install by running cabal install HDBC and cabal install HDBC-mysql if you have the Haskell platform installed. Let's start with the first two functions on the list, as these are both built into the HDBC library:
import Control.Monad
import Database.HDBC
import Database.HDBC.MySQL
import System.IO
import System.Directory
import Data.Time
import Data.Time.Calendar
main = do
conn <- connectMySQL defaultMySQLConnectInfo {
mysqlHost = "127.0.0.1",
mysqlUser = "root",
mysqlPassword = "pass",
mysqlDatabase = "test"
}
tables <- getTables conn
This part is fairly straight forward; we create the connection and then put the list of tables into a variable, called tables. The next function will loop through the list of tables and get all the rows in each one, a quick way to do this is to make a function that handles just one value, and then use the map function to apply it to the array. Since we are mapping an IO function, we have to use mapM. With this implemented, your code should now look like the following:
getQueryString name = "select * from " ++ name
processTable :: IConnection conn => conn -> String -> IO [[SqlValue]]
processTable conn name = do
let qu = getQueryString name
rows <- quickQuery' conn qu []
return rows
main = do
conn <- connectMySQL defaultMySQLConnectInfo {
mysqlHost = "127.0.0.1",
mysqlUser = "root",
mysqlPassword = "pass",
mysqlDatabase = "test"
}
tables <- getTables conn
rows <- mapM (processTable conn) tables
getQueryString is a pure function that returns a select query, and then we have the actual processTable function, which uses this query string to fetch all the rows from the specified table. Haskell is a strongly typed language, which basically means you can't, for instance, put an int where a string is supposed to go. But Haskell is also "type inferencing," which means you usually don't need to write the types and Haskell will figure it out. Here, we have a custom conn type, which I needed to declare explicitly; so that is what the line above the processTable function is doing.
The next thing on the list is to convert the SQL values that were returned by the previous function into strings. Another way to handle lists, besides map is to create a recursive function. In our program, we have three layers of lists: a list of SQL values, which are in a list of rows, which are in a list of tables. I will use map for the first two lists, and then a recursive function to handle the final one. This will allow the function itself to be pretty short. Here is the resulting function:
unSql x = (fromSql x) :: String sqlToArray [n] = (unSql n) : [] sqlToArray (n:n2) = (unSql n) : sqlToArray n2
Then, add the following line to the main function:
let stringRows = map (map sqlToArrays) rows
You may have noticed that, somtimes, variables are declared as var , and at other times, as let var = function. The rule is essentially, when you are attempting to run a IO function and place the results in a variable, you use the method; to store a pure function's results within a variable, you would instead use let.
The next part is going to be a little tricky. We have all the rows in string format, and, now, we have to replace each row of values with an insert string that MySQL will understand. The problem is that the table names are in a separate array; so a double map function won't really work in this case. We could have used map once, but then we would have to combine the lists into one - possibly using tuples because map only accepts one input parameter - so I decided that it would be simpler to just write new recursive functions. Since we have a three layer array, we are going to need three seperate recursive functions, so that each level can pass down its contents to the next layer. Here are the three functions along with a helper function to generate the actual SQL query:
flattenArgs [arg] = "\"" ++ arg ++ "\""
flattenArgs (arg1:args) = "\"" ++ arg1 ++ "\", " ++ (flattenArgs args)
iQuery name args = "insert into " ++ name ++ " values (" ++ (flattenArgs args) ++ ");\n"
insertStrRows name [arg] = iQuery name arg
insertStrRows name (arg1:args) = (iQuery name arg1) ++ (insertStrRows name args)
insertStrTables [table] [rows] = insertStrRows table rows : []
insertStrTables (table1:other) (rows1:etc) = (insertStrRows table1 rows1) : (insertStrTables other etc)
Again, add the following to the main function:
let insertStrs = insertStrTables tables stringRows
The flattenArgs and iQuery functions work together to create the actual SQL insert query. After that, we only have the two recursive functions. Notice that, in two of the three recursive functions, we input an array, but the function returns a string. By doing this, we are removing two of the nested arrays. Now, we only have one array with one output string per table. The last step is to actually write the data to their corresponding files; this is significantly easier, now that we're merely dealing with a simple array. Here is the last part along with the function to get the date:
dateStr = do
t <- getCurrentTime
return (showGregorian . utctDay $ t)
filename name time = "Backups/" ++ name ++ "_" ++ time ++ ".bac"
writeToFile name queries = do
let output = (deleteStr name) ++ queries
time <- dateStr
createDirectoryIfMissing False "Backups"
f <- openFile (filename name time) WriteMode
hPutStr f output
hClose f
writeFiles [n] [q] = writeToFile n q
writeFiles (n:n2) (q:q2) = do
writeFiles [n] [q]
writeFiles n2 q2
The dateStr function converts the current date into a string with the format, YYYY-MM-DD. Then, there is the filename function, which puts all the pieces of the filename together. The writeToFile function takes care of the outputting to the files. Lastly, the writeFiles function iterates through the list of tables, so you can have one file per table. All that's left to do is finish up the main function with the call to writeFiles, and add a message informing the user when it's finished. Once completed, your main function should look like so:
main = do
conn <- connectMySQL defaultMySQLConnectInfo {
mysqlHost = "127.0.0.1",
mysqlUser = "root",
mysqlPassword = "pass",
mysqlDatabase = "test"
}
tables <- getTables conn
rows <- mapM (processTable conn) tables
let stringRows = map (map sqlToArray) rows
let insertStrs = insertStrTables tables stringRows
writeFiles tables insertStrs
putStrLn "Databases Sucessfully Backed Up"
Now, if any of your databases ever lose their information, you can paste the SQL queries straight from their backup file into any MySQL terminal or program that can execute queries; it will restore the data to that point in time. You can also add a cron job to run this hourly or daily, in order to keep your backups up to date.
Finishing Up
There's an excellent book by Miran Lipovača, called "Learn you a Haskell".
That's all I have for this tutorial! Moving forward, if you are interested in fully learning Haskell, there are a few good resources to check out. There's an excellent book, by Miran Lipovača, called "Learn you a Haskell", which even has a free online version. That would be an excellent start.
If you are looking for specific functions, you should refer to Hoogle, which is a Google-like search engine that allows you to search by name, or even by type. So, if you need a function that converts a string to a list of strings, you would type String -> [String], and it will provide you with all of the applicable functions. There is also a site, called hackage.haskell.org, which contains the list of modules for Haskell; you can install them all through cabal.
I hope you've enjoyed this tutorial. If you have any questions at all, feel free to post a comment below; I'll do my best to get back to you as soon as possible!

Comments