Ever wondered about a quick way to tell what some document is focusing on? What is its main topic? Let me give you this simple trick. List the unique words mentioned in the document, and then check how many times each word has been mentioned (frequency). This way would give you an indication of what the document is mainly about. But that wouldn't work easily manually, so we need some automated process, don't we?
Yes, an automated process will make this much easier. Let's see how we can list the different unique words in a text file and check the frequency of each word using Python.
Test File
In this tutorial, we are going to use test.txt as our test file. Go ahead and download it, but don't open it! Let's make a small game. The text inside this test file is from one of my tutorials at Envato Tuts+. Based on the frequency of words, let's guess which of my tutorials this text was extracted from.
Let the game begin!
Regular Expressions
Since we are going to apply a pattern in our game, we need to use regular expressions (regex). If "regular expressions" is a new term to you, this is a nice definition from Wikipedia:
A sequence of characters that define a search pattern, mainly for use in pattern matching with strings, or string matching, i.e. "find and replace"-like operations. The concept arose in the 1950s, when the American mathematician Stephen Kleene formalized the description of a regular language, and came into common use with the Unix text processing utilities ed, an editor, and grep, a filter
If you want to know more about regular expressions before moving ahead with this tutorial, you can see my other tutorial Regular Expressions In Python, and come back again to continue this tutorial.
Building the Program
Let's work step by step on building this game. The first thing we want to do is to store the text file in a string variable.
document_text = open('test.txt', 'r')
text_string = document_text.read()
Now, in order to make applying our regular expression easier, let's turn all the letters in our document into lower case letters, using the lower() function, as follows:
text_string = document_text.read().lower()
Let's write our regular expression that would return all the words with the number of characters in the range [3-15]. Starting from 3 will help in avoiding words that we may not be interested in counting their frequency like if, of, in, etc., and words having a length larger than 15 might not be correct words. The regular expression for such a pattern looks as follows:
\b[a-z]{3,15}\b
\b is related to word boundary. For more information on the word boundary, you can check this tutorial.
The above regular expression can be written as follows:
match_pattern = re.search(r'\b[a-z]{3,15}\b', text_string)
Since we want to walk through multiple words in the document, we can use the findall function:
Return all non-overlapping matches of pattern in string, as a list of strings. The string is scanned left-to-right, and matches are returned in the order found. If one or more groups are present in the pattern, return a list of groups; this will be a list of tuples if the pattern has more than one group. Empty matches are included in the result unless they touch the beginning of another match.
At this point, we want to find the frequency of each word in the document. The suitable concept to use here is Python's Dictionaries, since we need key-value pairs, where key is the word, and the value represents the frequency words appeared in the document.
Assuming we have declared an empty dictionary frequency = { }, the above paragraph would look as follows:
for word in match_pattern:
count = frequency.get(word,0)
frequency[word] = count + 1
We can now see our keys using:
frequency_list = frequency.keys()
Finally, in order to get the word and its frequency (number of times it appeared in the text file), we can do the following:
for words in frequency_list:
print words, frequency[words]
Let's put the program together in the next section, and see what the output looks like.
Putting It All Together
Having discussed the program step by step, let's now see how the program looks:
import re
import string
frequency = {}
document_text = open('test.txt', 'r')
text_string = document_text.read().lower()
match_pattern = re.findall(r'\b[a-z]{3,15}\b', text_string)
for word in match_pattern:
count = frequency.get(word,0)
frequency[word] = count + 1
frequency_list = frequency.keys()
for words in frequency_list:
print words, frequency[words]
If you run the program, you should get something like the following:
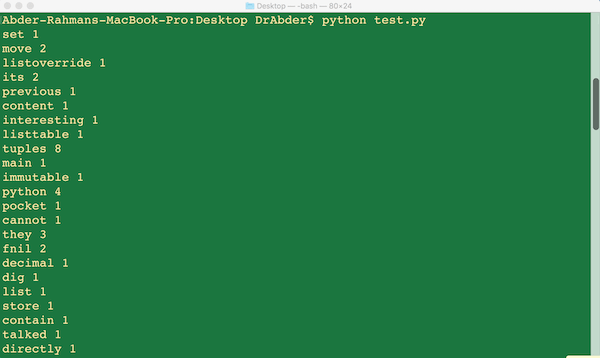
Let's come back to our game. Going through the word frequencies, what do you think the test file (with content from my other Python tutorial) was talking about?
(Hint: check the word with the maximum frequency).

Comments