During this year's WWDC, Apple introduced a number of significant improvements to Core Data, taking the framework to the next level. In this article, I'll zoom in on:
- Persistent Containers
- Xcode 8 Support and Swift 3
- Query Generations
- Concurrency Improvements
1. Persistent Containers
NSPersistentContainer
Setting up the Core Data stack has always been a bit of a pain. Because it is the first concept developers new to the framework need to become familiar with, the learning curve has always been fairly steep. This is no longer true.
The team at Apple introduced a brand new member to the framework, which makes setting up and managing the Core Data stack of your application a breeze. This new member is the NSPersistentContainer class.
Setting up the Core Data stack is trivial with the NSPersistentContainer class. You can initialize an instance by invoking the init(name:) initializer. The name you pass to the initializer is used by the persistent container to find the data model in the application bundle, and it is also used to name the persistent store of the application.
let persistentContainer = NSPersistentContainer(name: "MyApplication")
The persistent container creates a persistent store coordinator, a managed object model, and a managed object context. It exposes several properties and methods to interact with the Core Data stack.
You can access a managed object context that is associated with the main queue of the application through the viewContext property of the NSPersistentContainer instance. As the name implies, this managed object context is meant to be used for any operations that relate to the user interface of the application.
You can also access the persistent store coordinator and the managed object model through the persistentStoreCoordinator and managedObjectModel properties.
If you need to perform a Core Data operation in the background, you can ask the persistent container for a private managed object context by invoking the newBackgroundContext() factory method. For lightweight operations, you can invoke the performBackgroundTask(_:) method. This method accepts a closure in which you can perform the background operation using a private managed object context.
NSPersistentStoreDescription
Apple also introduced the NSPersistentStoreDescription class. It encapsulates the information to create and load a persistent store, such as the location of the persistent store, its configuration, and whether it is a read-only persistent store.
Adding a persistent store to a persistent store coordinator is much more elegant using the NSPersistentStoreDescription class. The NSPersistentStoreCoordinator class defines a new method, addPersistentStore(with:completionHandler:), which accepts an NSPersistentStoreDescription instance and a completion handler.
// Create Persistent Store Description
let persistentStoreDescription = NSPersistentStoreDescription(url: url)
// Add Persistent Store to Persistent Store Coordinator
persistentContainer.persistentStoreCoordinator.addPersistentStore(with: persistentStoreDescription, completionHandler: { (persistentStoreDescription, error) in
if let error = error {
print("Unable to Add Persistent Store")
print("\(error), \(error.localizedDescription)")
} else {
// Successfully Added Persistent Store
}
}
Xcode 8 and Swift 3
Xcode 8
Xcode 8 also includes a number of changes that dramatically improve support for Core Data. Xcode now automatically generates NSManagedObject subclasses for every entity of the data model. And instead of adding the files for the subclasses to the project, cluttering up the project, they are added to the Derived Data folder. This means that Xcode can make sure they are updated when the data model changes, and you the developer don't need to worry about the files.
How does it work? If you open the data model of your project in Xcode 8 and select an entity, you see a new option in the Data Model Inspector on the right. The Codegen field in the Class section is what interests us.
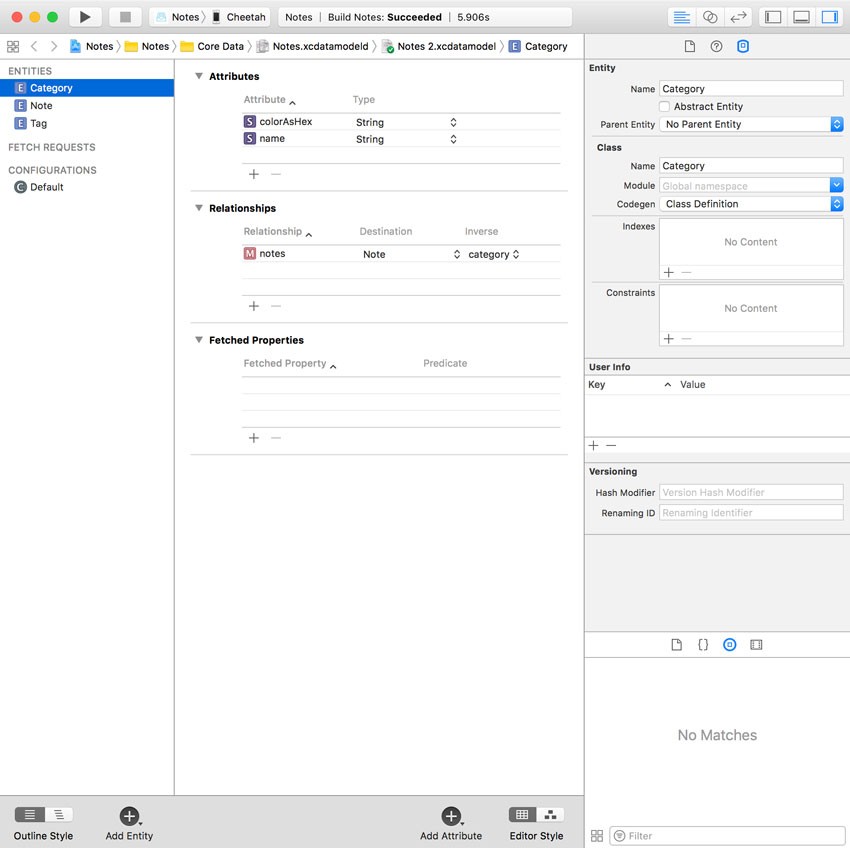
As of Xcode 8.1, the value of this field is automatically set to Class Definition. This means that Xcode generates an NSManagedObject subclass for the selected entity. If you make any changes to the entity, the generated class is automatically updated for you. You don't need to worry about anything.
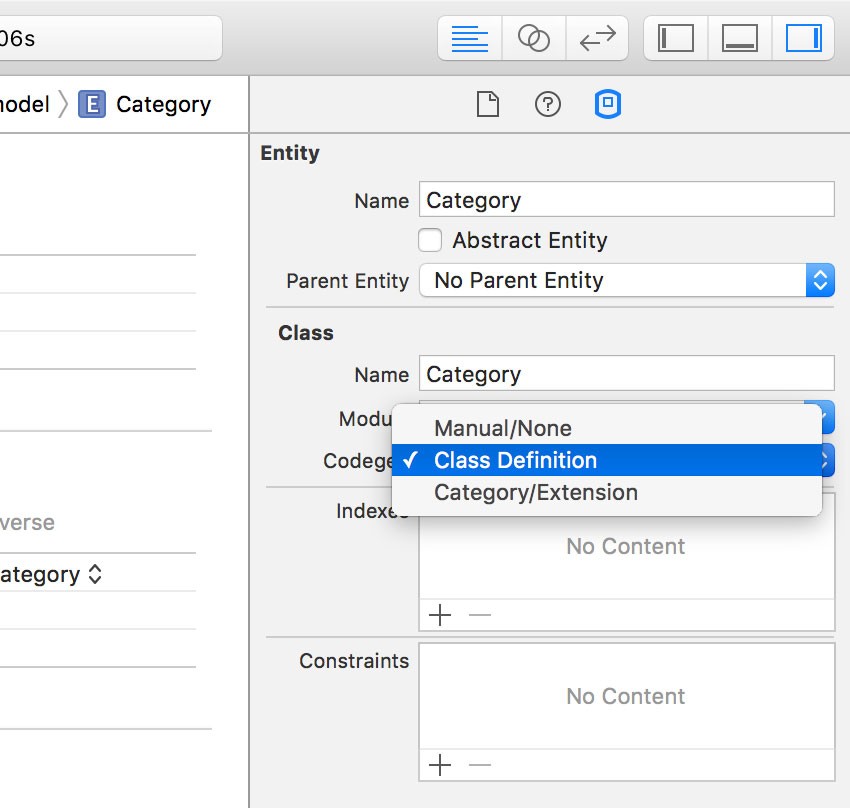
You can disable code generation, or you can instruct Xcode to only generate an extension (Swift) or category (Objective-C) for the class. If you choose the latter option, then you are in charge of creating an NSManagedObject subclass for the entity.
Simplifying Core Data
The Core Data framework also defines a new protocol, NSFetchedResultsType, which makes working with the framework much easier and more elegant in Swift. This is what it used to take to create a new managed object for the Category entity.
if let entity = NSEntityDescription.entity(forEntityName: "Category", in: managedObjectContext) {
let category = Category(entity: entity, insertInto: managedObjectContext)
}
As of iOS 10 and macOS 10.12, every NSManagedObject subclass knows what entity it belongs to.
category.entity
This means we only need to specify in which managed object context the managed object needs to be created.
let category = Category(context: managedObjectContext)
I'm sure you agree that this looks much more elegant and concise. Creating fetch requests is also much easier. Take a look at the example below.
let fetchRequest = Category.fetchRequest()
What I am showing you is only a subset of the improvements available in iOS 10, tvOS 10, macOS 10.12, and watchOS 3. There is much more for you to explore.
Query Generations
The most important announcement is probably the introduction of query generations. Query generations solve a problem that has been plaguing Core Data ever since it was released more than ten years ago.
What Problem Does It Solve?
Faulting is an essential aspect of the framework. It ensures Core Data performs well, and it also keeps the framework's memory footprint low. If you want to learn more about faulting, then I recommend another article I wrote last year.
Even though faulting works great and is essential for the framework, it can go wrong when a fault can no longer be fulfilled. This scenario can be avoided by deleting inaccessible faults—that is, faults that can no longer be fulfilled. But this is merely a workaround and can lead to unexpected behavior in your application.
Alternatively, the application can aggressively fetch every piece of data it needs from the persistent store, bypassing faulting. This results in decreased performance and a larger memory footprint. In other words, you disable one of the key features of the framework.
Query generations provide another solution that tackles the root of the problem. The idea is simple. The execution is a bit more complicated.
What Is It?
As of iOS 10 and macOS 10.12, it is possible to assign a query generation to a managed object context. This means that the managed object context interacts with a snapshot of the data stored in the persistent store. Even if other managed object contexts make changes (inserts, deletes, and updates), the snapshot of the managed object context remains unchanged.
The upside is that data cannot change from underneath the managed object context. In other words, the managed object context works with a specific generation of data, hence the name query generations.
How Does It Work?
A managed object context has three options to work with query generations. The first option doesn't change anything. The managed object context doesn't pin itself to a query generation. If the data of the persistent store changes, the managed object context needs to deal with that. This is the behavior you are used to, which can lead to inaccessible faults.
Alternatively, the managed object context can pin itself to a query generation the moment it loads data from the persistent store. As a third option, the managed object context can pin itself to a specific query generation.
Even though query generations are a more advanced concept of the Core Data framework, they solve a problem anyone working with Core Data faces at some point. The more complex your application, the more serious the problem is. It is great to see that the framework now provides a solution to this problem.
Concurrency Improvements
As I mentioned earlier, the improvements made to the Core Data framework have been nothing short of amazing. The improvements range from new classes that make working with the framework easier to resolving performance issues at the level of the persistent store coordinator.
Another improvement made to the framework relates to concurrency. Even though the persistent store coordinator should not be used on multiple threads, it knows how to lock itself when different managed object contexts access the persistent store coordinator from different threads. If the persistent store coordinator is locked when it is accessed by a managed object context, other managed object contexts need to wait for the lock to be removed before they can access the persistent store coordinator. This can cause performance problems, which can trickle up to the user interface, resulting in decreased performance.
As of iOS 10 and macOS 10.12, the persistent store coordinator no longer takes a lock when a managed object context pushes changes to the persistent store coordinator. Instead, the persistent store sends the requests of the persistent store coordinator immediately to the SQL store itself. Instead, the lock is taken at the level of the SQL store.
There are several important benefits to this approach. It is no longer necessary to use multiple Core Data stacks to avoid performance issues. This means that the architecture of your application can be simplified dramatically, even for large and complex applications.
Because this solution is implemented at the level of the SQL store, it is only available if your application uses a SQLite store as its persistent store. If your application uses multiple persistent stores, then each of these stores needs to be a SQLite store. This feature is enabled by default.
Conclusion
Core Data continues to improve year over year. It is fantastic to see that Apple is committed to making its persistence solution better with every iteration of its platforms. Even though there are alternative solutions available, such as Realm, my preferred choice continues to be Core Data.
To learn more about Core Data, check out my Core Data and Swift series here on Envato Tuts+.
 Core DataCore Data and Swift: Core Data Stack
Core DataCore Data and Swift: Core Data Stack Core DataCore Data and Swift: Data Model
Core DataCore Data and Swift: Data Model Core DataCore Data and Swift: Managed Objects and Fetch Requests
Core DataCore Data and Swift: Managed Objects and Fetch Requests Core DataCore Data and Swift: Relationships and More Fetching
Core DataCore Data and Swift: Relationships and More Fetching Core DataCore Data and Swift: NSFetchedResultsController
Core DataCore Data and Swift: NSFetchedResultsController Core DataCore Data and Swift: More NSFetchedResultsController
Core DataCore Data and Swift: More NSFetchedResultsController

Comments