Simply put, a remote repository is one that is not your own. It could be on a central server, another developer's personal computer, or even your file system. As long as you can access it from some kind of network protocol, Git makes it incredibly easy to share contributions with other repositories.
The primary role of remote repositories is to represent other developers within your own repository. Branches, on the other hand, should only deal with project development. That is to say, don't try to give every developer his or her own branch to work on-give each a complete repository and reserve branches for developing features.
This chapter begins by covering the mechanics of remotes, and then presents the two most common workflows of Git-based collaboration: the centralized workflow and the integrator workflow.
Manipulating Remotes
Similar to git branch, the git remote command is used to manage connections to other repositories. Remotes are nothing more than bookmarks to other repositories-instead of typing the full path, they let you reference it with a user-friendly name. We'll learn how we can use these bookmarks within Git Below.
Listing Remotes
You can view your existing remotes by calling the git remote command with no arguments:
git remote
If you have no remotes, this command won't output any information. If you used git clone to get your repository, you'll see an origin remote. Git automatically adds this connection, under the assumption that you'll probably want to interact with it down the road.
You can request a little bit more information about your remotes with the -v flag:
git remote –v
This displays the complete path to the repository. Specifying remote paths is discussed in the next section.
Creating Remotes
The git remote add command creates a new connection to a remote repository.
git remote add <name> <path-to-repo>
After running this command, you can reach the Git repository at <path-to-repo> using <name>. Again, this is simply a convenient bookmark for a long path name-it does not create a direct link into someone else's repository.
Git accepts many network protocols for specifying the location of a remote repository, including file://, ssh://, http://, and its custom git:// protocol. For example:
git remote add some-user ssh://[email protected]/some-user/some-repo.git
After running this command, you can access the repository at github.com/some-user/some-repo.git using only some-user. Since we used ssh:// as the protocol, you'll probably be prompted for an SSH password before you're allowed to do anything with the account. This makes SSH a good choice for granting write access to developers, whereas HTTP paths are generally used to give read-only access. As we'll soon discover, this is designed as a security feature for distributed environments.
Deleting Remotes
Finally, you can delete a remote connection with the following command:
git remote rm <remote-name>
Remote Branches
Commits may be the atomic unit of Git-based version control, but branches are the medium in which remote repositories communicate. Remote branches act just like the local branches we've covered thus far, except they represent a branch in someone else's repository.
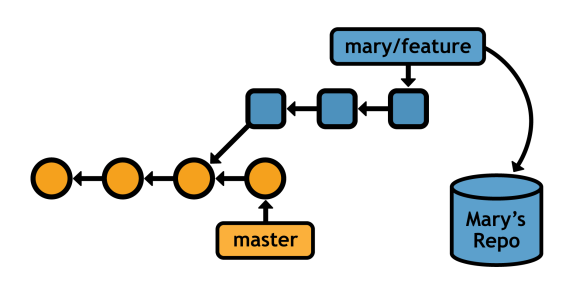
Once you've downloaded a remote branch, you can inspect, merge, and extend it like any other branch. This makes for a very short learning curve if you understand how to use branches locally.
Fetching Remote Branches
The act of downloading branches from another repository is called fetching. To fetch a remote branch, you can specify the repository and the branch you're looking for:
git fetch <remote> <branch>
Or, if you want to download every branch in <remote>, simply omit the branch name. After fetching, you can see the downloaded branches by passing the -r option to git branch:
git branch –r
This gives you a branch listing that looks something like:
origin/master origin/some-feature origin/another-feature
Remote branches are always prefixed with the remote name (origin/) to distinguish them from local branches.
Remember, Git uses remote repositories as bookmarks-not real-time connections with other repositories. Remote branches are copies of the local branches of another repository. Outside of the actual fetch, repositories are completely isolated development environments. This also means Git will never automatically fetch branches to access updated information-you must do this manually.
But, this is a good thing, since it means you don't have to constantly worry about what everyone else is contributing while doing your work. This is only possible due to the non-linear workflow enabled by Git branches.
Inspecting Remote Branches
For all intents and purposes, remote branches behave like read-only branches. You can safely inspect their history and view their commits via git checkout, but you cannot continue developing them before integrating them into your local repository. This makes sense when you consider the fact that remote branches are copies of other users' commits.
The .. syntax is very useful for filtering log history. For example, the following command displays any new updates from origin/master that are not in your local master branch. It's generally a good idea to run this before merging changes so you know exactly what you're integrating:
git log master..origin/master
If this outputs any commits, it means you are behind the official project and you should probably update your repository. This is described in the next section.
It is possible to checkout remote branches, but it will put you in a detached HEAD state. This is safe for viewing other user's changes before integrating them, but any changes you add will be lost unless you create a new local branch tip to reference them.
Merging/Rebasing
Of course, the whole point of fetching is to integrate the resulting remote branches into your local project. Let's say you're a contributor to an open-source project, and you've been working on a feature called some-feature. As the "official" project (typically pointed to by origin) moves forward, you may want to incorporate its new commits into your repository. This would ensure that your feature still works with the bleeding-edge developments.
Fortunately, you can use the exact same git merge command to incorporate changes from origin/master into your feature branch:
git checkout some-feature git fetch origin git merge origin/master
Since your history has diverged, this results in a 3-way merge, after which your some-feature branch has access to the most up-to-date version of the official project.
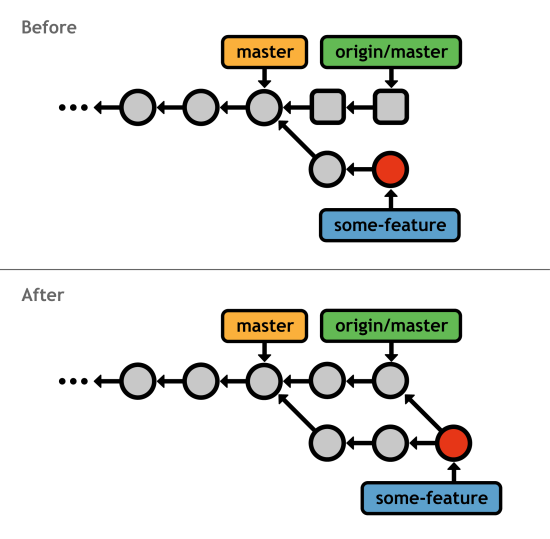
master into a feature branchHowever, frequently merging with origin/master just to pull in updates eventually results in a history littered with meaningless merge commits. Depending on how closely your feature needs to track the rest of the code base, rebasing might be a better way to integrate changes:
git checkout some-feature git fetch origin git rebase origin/master
As with local rebasing, this creates a perfectly linear history free of superfluous merge commits:
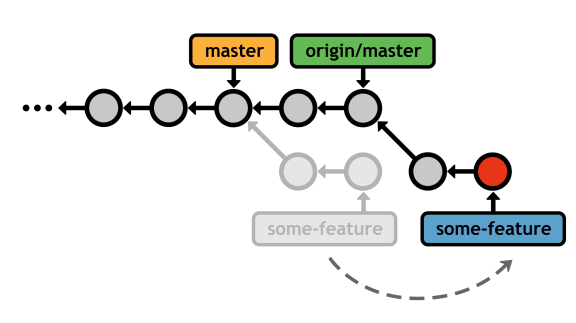
masterRebasing/merging remote branches has the exact same trade-offs as discussed in the chapter on local branches.
Pulling
Since the fetch/merge sequence is such a common occurrence in distributed development, Git provides a pull command as a convenient shortcut:
git pull origin/master
This fetches the origin's master branch, and then merges it into the current branch in one step. You can also pass the --rebase option to use git rebase instead of git merge.
Pushing
To complement the git fetch command, Git also provides a push command. Pushing is almost the opposite of fetching, in that fetching imports branches, while pushing exports branches to another repository.
git push <remote> <branch>
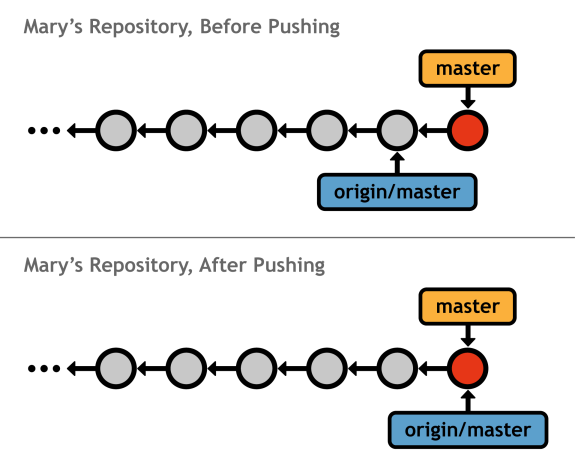
The above command sends the local <branch> to the specified remote repository. Except, instead of a remote branch, git push creates a local branch. For example, executing git push mary my-feature in your local repository will look like the following from Mary's perspective (your repository will be unaffected by the push).
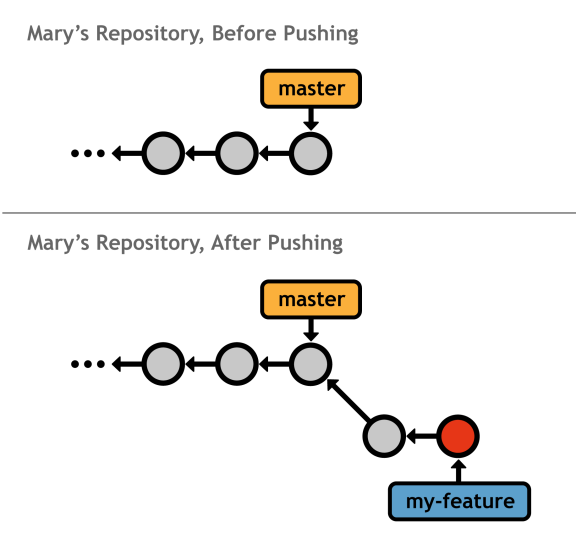
Notice that my-feature is a local branch in Mary's repository, whereas it would be a remote branch had she fetched it herself.
This makes pushing a dangerous operation. Imagine you're developing in your own local repository, when, all of a sudden, a new local branch shows up out of nowhere. But, repositories are supposed to serve as completely isolated development environments, so why should git push even exist? As we'll discover shortly, pushing is a necessary tool for maintaining public Git repositories.
Remote Workflows
Now that we have a basic idea of how Git interacts with other repositories, we can discuss the real-world workflows that are supported by these commands. The two most common collaboration models are: the centralized workflow and the integrator workflow. SVN and CVS users should be quite comfortable with Git's flavor of centralized development, but using Git means you'll also be able to leverage its highly-efficient merge capabilities. The integrator workflow is a typical distributed collaboration model and is not possible in purely centralized systems.
As you read through these workflows, keep in mind that Git treats all repositories as equals. There is no "master" repository according to Git as there is with SVN or CVS. The "official" code base is merely a project convention-the only reason it's the official repository is because that's where everyone's origin remote points.
Public (Bare) Repositories
Every collaboration model involves at least one public repository that serves as a point-of-entry for multiple developers. Public repositories have the unique constraint of being bare-they must not have a working directory. This prevents developers from accidentally overwriting each others' work with git push. You can create a bare repository by passing the --bare option to git init:
git init --bare <path>
Public repositories should only function as storage facilities-not development environments. This is conveyed by adding a .git extension to the repository's file path, since the internal repository database resides in the project root instead of the .git subdirectory. So, a complete example might look like:
git init --bare some-repo.git
Aside from a lack of a working directory, there is nothing special about a bare repository. You can add remote connections, push to it, and pull from it in the usual fashion.
The Centralized Workflow
The centralized workflow is best suited to small teams where each developer has write access to the repository. It allows collaboration by using a single central repository, much like the SVN or CVS workflow. In this model, all changes must be shared through the central repository, which is usually stored on a server to enable Internet-based collaboration.
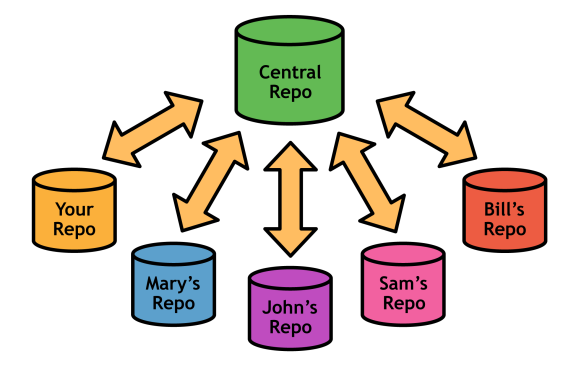
Developers individually work in their own local repository, which is completely isolated from everyone else. Once they've completed a feature and are ready to share their code, they clean it up, integrate it into their local master, and push it to the central repository (e.g., origin). This also means each developer needs SSH access to the central repository.
Then, everyone else can fetch the new commits and incorporate them into their local projects. Again, this can be done with either a merge or a rebase, depending on your team's conventions.
This is the core process behind centralized workflows, but it hits a bump when multiple users try to simultaneously update the central repository. Imagine a scenario where two developers finished a feature, merged it into their local master, and tried to publish it at the same time (or close to it).
Whoever gets to the server first can push their commits as normal, but then the second developer gets stuck with a divergent history, and Git cannot perform a fast-forward merge. For example, if a developer named John were to push his changes right before Mary, we'd see a conflict in Mary's repository:
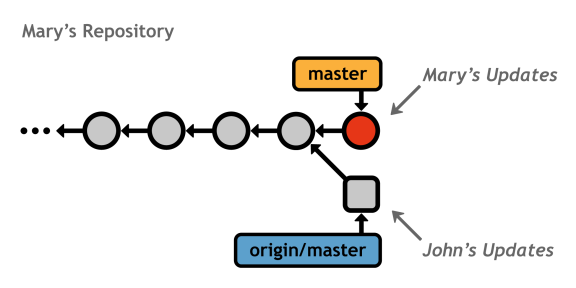
The only way to make the origin's master (updated by John) match Mary's master is to overwrite John's commit. Obviously, this would be very bad, so Git aborts the push and outputs an error message:
! [rejected] master -> master (non-fast-forward) error: failed to push some refs to 'some-repo.git'
To remedy this situation, Mary needs to synchronize with the central repository. Then, she'll be able to push her changes in the usual fashion.
git fetch origin master git rebase origin/master git push origin master
Other than that, the centralized workflow is relatively straightforward. Each developer stays in his or her own local repository, periodically pulling/pushing to the central repository to keep everything up-to-date. It's a convenient workflow to set up, as only one server is required, and it leverages existing SSH functionality.
The Integrator Workflow
The integrator workflow is a distributed development model where all users maintain their own public repository, in addition to their private one. It exists as a solution to the security and scalability problems inherent in the centralized workflow.
The main drawback of the centralized workflow is that every developer needs push access to the entire project. This is fine if you're working with a small team of trusted developers, but imagine a scenario where you're working on an open-source software project and a stranger found a bug, fixed it, and wants to incorporate the update into the main project. You probably don't want to give him or her push access to the central repository, since he or she could start pushing all sorts of random commits, and you would effectively lose control of the project.
But, what you can do is tell the contributor to push the changes to his or her own public repository. Then, you can pull his bug fix into your private repository to ensure it doesn't contain any undeclared code. If you approve his contributions, all you have to do is merge them into a local branch and push it to the main repository as usual. You've become an integrator, in addition to an ordinary developer:
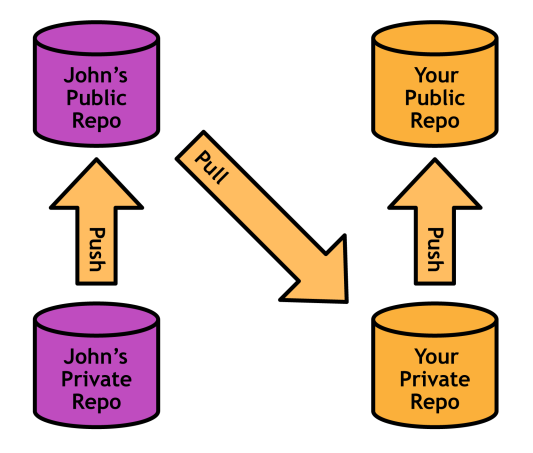
In this workflow, each developer only needs push access to his or her own public repository. The contributor uses SSH to push to his or her public repository, but the integrator can fetch the changes over HTTP (a read-only protocol). This makes for a more secure environment for everyone, even when you add more collaborators:
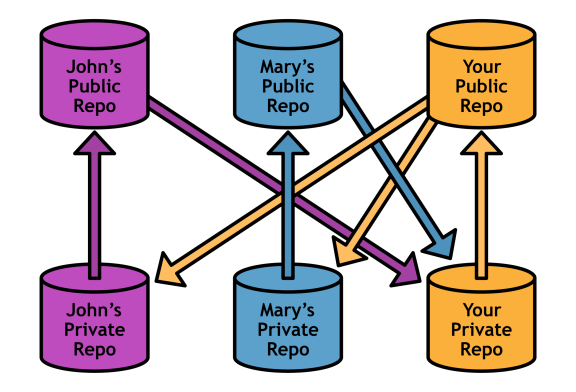
Note that the team must still agree on a single "official" repository to pull from-otherwise changes would be applied out-of-order and everyone would wind up out-of-sync very quickly. In the above diagram, "Your Public Repo" is the official project.
As an integrator, you have to keep track of more remotes than you would in the centralized workflow, but this gives you the freedom and security to incorporate changes from any developer without threatening the stability of the project.
In addition, the integrator workflow has no single point-of-access to serve as a choke point for collaboration. In centralized workflows, everyone must be completely up-to-date before publishing changes, but that is not the case in distributed workflows. Again, this is a direct result of the nonlinear development style enabled by Git's branch implementation.
These are huge advantages for large open-source projects. Organizing hundreds of developers to work on a single project would not be possible without the security and scalability of distributed collaboration.
Conclusion
Supporting these centralized and distributed collaboration models was all Git was ever meant to do. The working directory, the stage, commits, branches, and remotes were all specifically designed to enable these workflows, and virtually everything in Git revolves around these components.
True to the UNIX philosophy, Git was designed as a suite of interoperable tools, not a single monolithic program. As you continue to explore Git's numerous capabilities, you'll find that it's very easy to adapt individual commands to entirely novel workflows.
I now leave it to you to apply these concepts to real-world projects, but as you begin to incorporate Git into your daily workflow, remember that it's not a silver bullet for project management. It is merely a tool for tracking your files, and no amount of intimate Git knowledge can make up for a haphazard set of conventions within a development team.
This lesson represents a chapter from Git Succinctly, a free eBook from the team at Syncfusion.

Comments